前言
接前几节内容,django处理一次请求完整的生命周期如下:
-> URL对应关系(匹配) -> 视图函数处理 -> 返回用户字符串或html等内容
其中第一个,即是url匹配,在django中,支持多种匹配方式,下面罗列整理一下
一、基础匹配
1 | url(r'^index/', views.index), |
参考:Django(二)、Http请求处理,此处不再赘述。
此方式的匹配逻辑比较简单,为了满足更多的需求,因此引入正则匹配
二、正则匹配
在django urls匹配法则中,默认将链接中匹配到的元素提取出来,作为参数,传递给视图函数处理,可以提取多个匹配元素,按照顺序作为参数传递,也可以分别多参数进行命名,这样就无需考虑传参顺序了。
例如:在页面中点击”详细信息”查看更多
urls.py写法:1
2url(r'^index_test/', enginetest_views.index_test),
url(r'^index-detail-(\d+).html', enginetest_views.index_detail),
视图函数写法:
1 | infodict={"id":1,"name":"alice","age":"20","email":"a@xxx.com"} |
对应模板页面:
index_test.html:
1 | <h2>INFO:</h2> |
index_detail.html:
1 | <h1>INFO DETAIL</h1> |
效果如下:
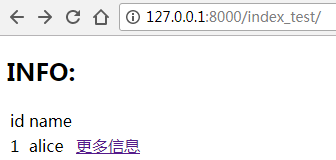
点击“更多信息”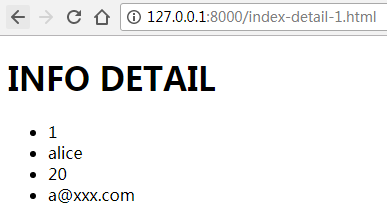
这里可以发现:url(r'^index-detail-(\d+).html', enginetest_views.index_detail),
中,(\d+)匹配到的数字,传递给了视图函数index_detail(request,uid)中的形参uid,作为其实参。
若匹配到的元素有多个,则依次作为参数传递给视图函数。
例如:url(r'^index-detail-(\d+)-(\d+).html', enginetest_views.index_detail),
则函数需接收两个参数:def index_detail(request,uid,nid)当参数的个数更多时,可以写作:def index_detail(request,*args,**kwargs)`
但以上方式接收函数,传递参数的顺序及接收参数的实参顺序必须一一对应,因此,为了避免顺序混乱造成的影响,建议使用如下方式,在urls绑定时,予以声明,例如:
1 | url(r'^index-detail-(?P<uid>\d+)-(?P<nid>\d+).html', views.detail) |
三、多级路由
在项目中,一个项目可能包含多个子程序,若将所有的路由绑定全部写在主程序的目录中,大量的路由绑定条目会使程序看起来比较臃肿,不利于分工合作。因此,django也支持多级路由,首先在子程序目录中创建urls.py文件,在主程序中指定某条件的路由,全部跳转向二级子程序urls.py中,再在子程序中写明细路由。
例如:
主程序urls.py:
1 | from django.conf.urls import url,include |
子程序cmdb/urls.py:
1 | #Author :ywq |
这样,django在匹配url时,会将主程序,以及子程序的匹配条件进行拼接,主程序的条件是’^cmdb’,子程序的条件是’/‘,’^_search/‘,那么合并就是’^cmdb/‘,’^cmdb_search/‘

