##
前言
前面几篇文章介绍了k8s的部署、对外服务、集群网络、微服务支持,在生产环境中使用,离不开运行状态监控,本篇开始部署使用prometheus,被各大公司广泛使用的容器监控工具。
工作方式
Prometheus工作示意图: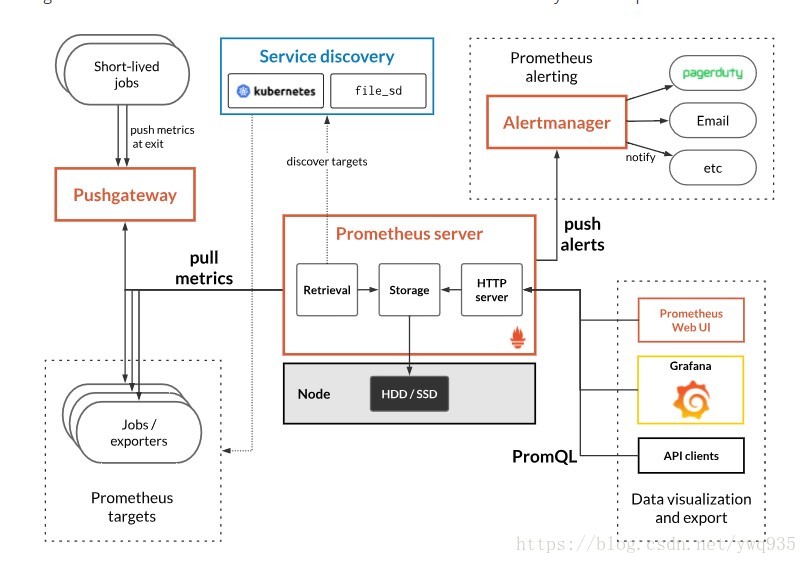
在k8s中,关于集群的资源有metrics度量值的概念,有各种不同的exporter可以通过api接口对外提供各种度量值的及时数据,prometheus在与k8s融合工作的过程,就是通过与这些提供metric值得exporter进行交互,获取数据,整合数据,展示数据,触发告警的过程。
一、获取metrics:
1.对短暂生命周期的任务,采取拉的形式获取metrics (不常见)
2.对于exporter提供的metrics,采取拉的方式获取metrics(通常方式),对接的exporter常见的有:kube-apiserver 、cadvisor、node-exporter,也可根据应用类型部署相应的exporter,获取该应用的状态信息,目前支持的应用有:nginx/haproxy/mysql/redis/memcache等。
二、数据汇总及按需获取:
可以按照官方定义的expr表达式格式,以及PromQL语法对相应的指标进程过滤,数据展示及图形展示。不过自带的webui较为简陋,但prometheus同时提供获取数据的api,grafana可通过api获取prometheus数据源,来绘制更精细的图形效果用以展示。
expr书写格式及语法参考官方文档:
https://prometheus.io/docs/prometheus/latest/querying/basics/
三、告警推送
prometheus支持多种告警媒介,对满足条件的告警自动触发告警,并可对告警的发送规则进行定制,例如重复间隔、路由等,可以实现非常灵活的告警触发。
部署
1.配置configmap,在部署前将Prometheus主程序配置文件准备好,以configmap的形式挂载进deployment中。
prometheus-configmap.yaml:
1 | apiVersion: v1 |
2.部署prometheus工作主程序,注意挂载上面的configmap:
prometheus.deploy.yml:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48apiVersion: apps/v1beta2
kind: Deployment
metadata:
labels:
name: prometheus-deployment
name: prometheus
namespace: kube-system
spec:
replicas: 1
selector:
matchLabels:
app: prometheus
template:
metadata:
labels:
app: prometheus
spec:
containers:
- image: prom/prometheus:v2.0.0
name: prometheus
command:
- "/bin/prometheus"
args:
- "--config.file=/etc/prometheus/prometheus.yml"
- "--storage.tsdb.path=/prometheus"
- "--storage.tsdb.retention=24h"
ports:
- containerPort: 9090
protocol: TCP
volumeMounts:
- mountPath: "/prometheus"
name: data
- mountPath: "/etc/prometheus"
name: config-volume
resources:
requests:
cpu: 100m
memory: 100Mi
limits:
cpu: 500m
memory: 2500Mi
serviceAccountName: prometheus
volumes:
- name: data
emptyDir: {}
- name: config-volume
configMap:
name: prometheus-config
3.部署svc、ingress、rbac授权。
注意:在本地是使用traefik做对外服务代理的,因此修改了默认的NodePort的svc.type为ClusterIP的方式,添加ingress后,可以以域名方式直接访问。若不做代理,可以无需部署ingress,svc.type使用默认的NodePort。
prometheus.svc.yaml:
1 | kind: Service |
prometheus.ing.yaml:
1 | apiVersion: extensions/v1beta1 |
rbac-setup.yaml:
1 | kind: ClusterRole |
依次部署上方几个yaml文件,待初始化完成后,配置好dns记录,即可打开浏览器访问: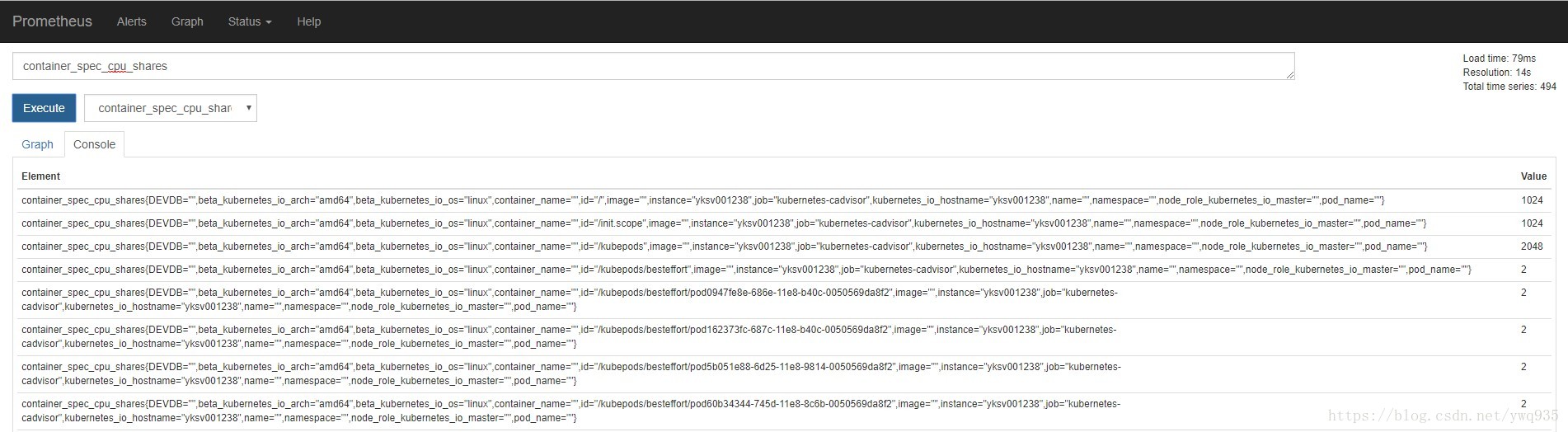
随便选取一个metric,点击execute,查看是否能正常获取结果输出。点击status—target,可以看到metrics的数据来源,即各exporter,点击相应exporter上的链接可查看这个exporter提供的metrics明细。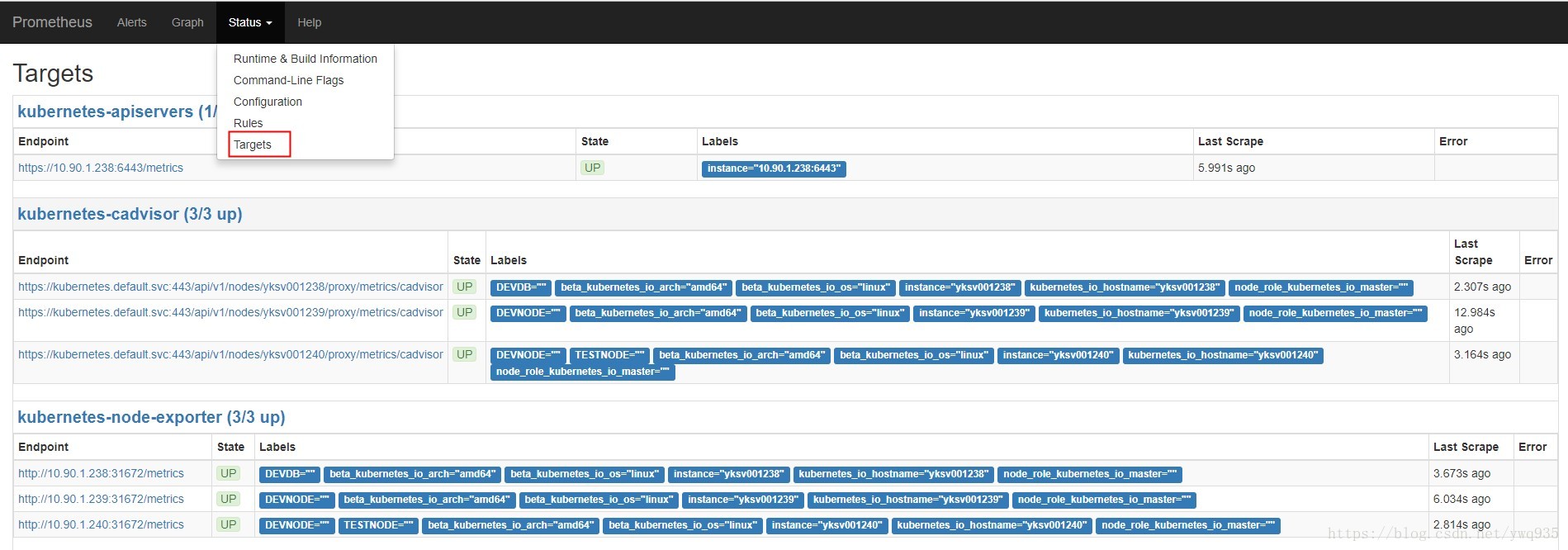
为了更好的展示图形效果,需要部署grafana,因此前已经部署有grafana,这里不再部署,贴一个all-in-one.yaml部署文件。
grafana-all-in-one.yaml:
1 | apiVersion: extensions/v1beta1 |
访问grafana,添加prometheus数据源:
默认管理账号密码为admin admin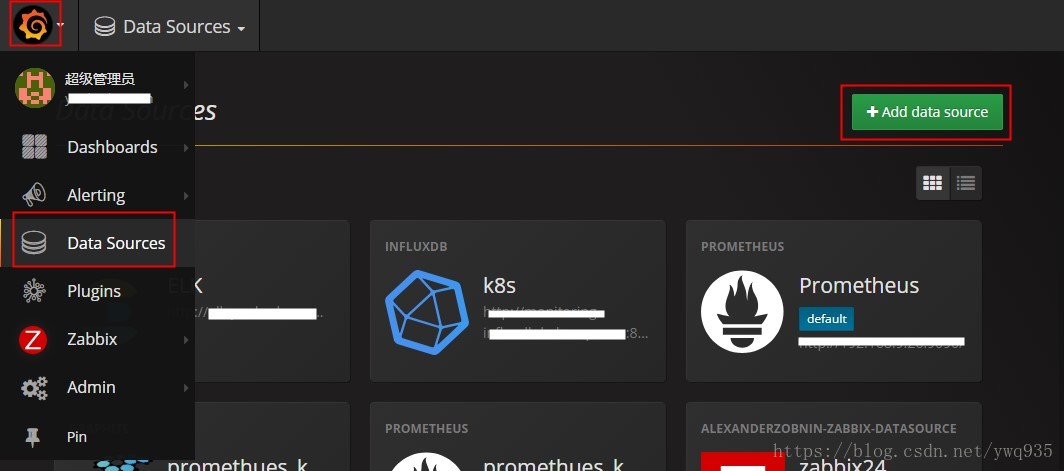
选择资源类型,填入prometheus的服务地址及端口号,点击保存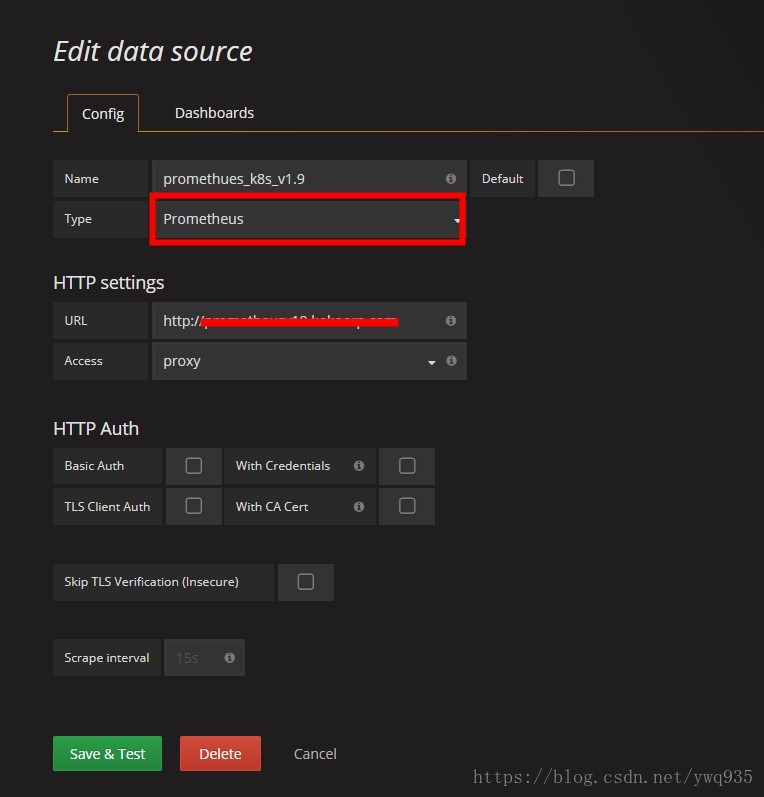
导入展示模板:
点击dashboard,点击import dashboard,在弹出框内填写数字315,会自动加载官方提供的315号模板,然后选择数据源为刚添加的数据源,模板就创建好了,非常easy。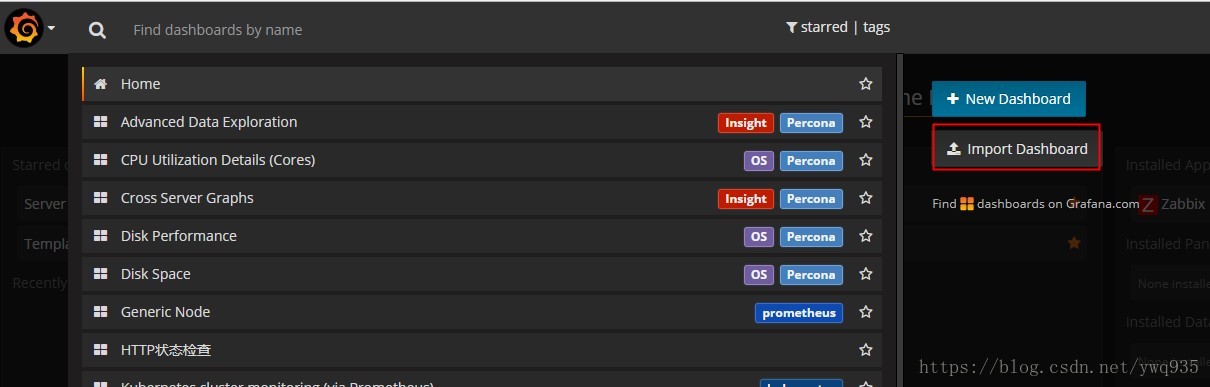
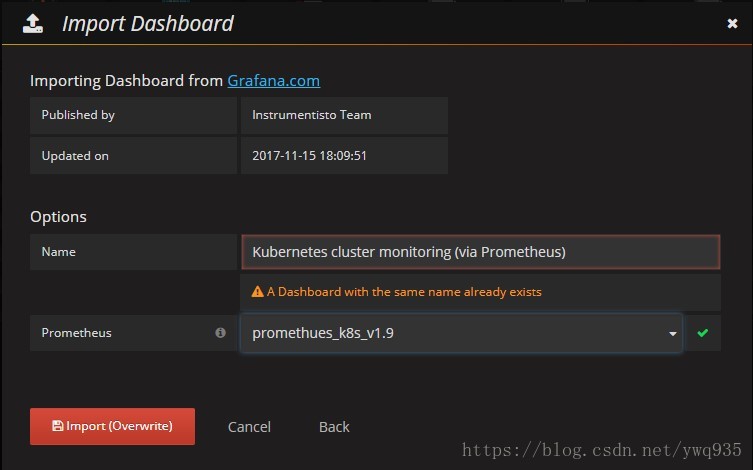
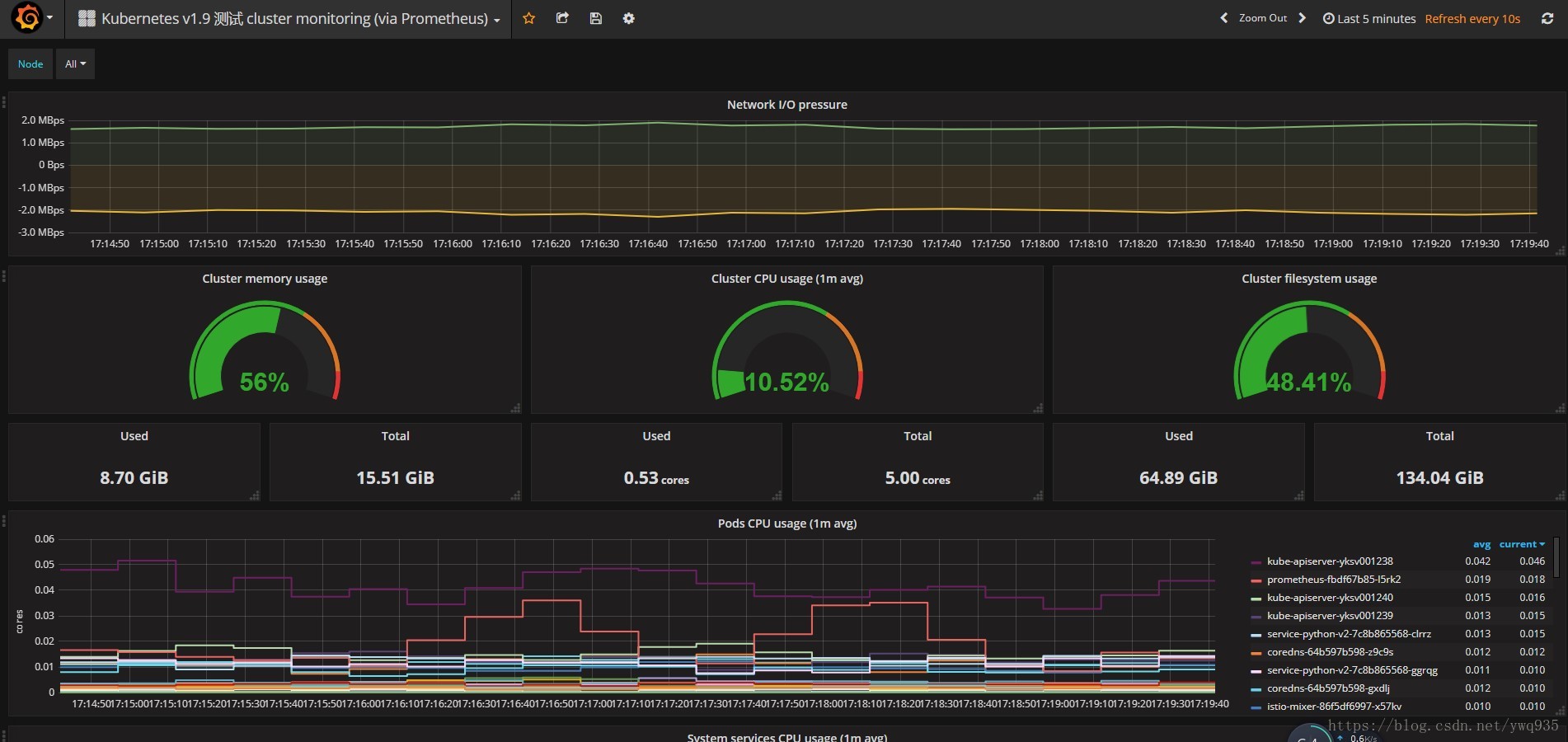
基本部署到这里就结束了,下篇介绍一下prometheus的告警相关规则。
===========================================================================================
7.19更新:
最近发现,采用daemon-set方式部署的node-exporterc采集到的度量值不准确,最后发现需要将host的/proc和/sys目录挂载进node-exporter的容器内。
更新后的node-exporter.yaml文件:
1 | apiVersion: extensions/v1beta1 |
NodePort
selector:
k8s-app: node-exporter1
2
3但是发现,部署完成之后,采集到的node指标依然不准确,非常奇怪,尝试脱离k8s使用docker方式直接部署,结果采集到的node数值就很准确了,有点不明白原因,后续继续排查一下。
docker运行命令:
docker run -d \
-p 9100:9100 \
–name node-exporter \
-v “/proc:/host/proc” \
-v “/sys:/host/sys” \
-v “/:/rootfs” \
–net=”host” \
prom/node-exporter:v0.14.0 \
-collector.procfs /host/proc \
-collector.sysfs /host/sys \
-collector.filesystem.ignored-mount-points “^/(sys|proc|dev|host|etc)($|/)”`
最后,记得修改configmap内的job相关targets配置。
为什么依附于k8s集群内采集的node指标就不准确,这个问题后续得好好研究,这次先到这里。

