前言
上一篇主要介绍prometheus基础告警相关,本篇再进行扩展,加入mysql监控,整理出一些监控告警表达式及配置文件,以及部署prometheus 2.0版之后支持的联邦job,多prometheus分支数据聚合,在多集群环境中很适用。
mysqld-exporter部署:
在公司的环境中,大部分的DB已迁移至K8S内运行,因此再以常见的节点二进制安装部署mysqld-exporter的方式不再适用。在本地k8s环境中,采取单pod包含多容器镜像的方式,为原本的DB pod实例多注入一个mysql-exporter的方式,对两者进行整合为一体部署,类似此前文章里istio的注入。
注入后的deployment文件的spec.template.spec.containers变更如下:
1 | spec: |
额外多增加一个mysql-exporter的容器,并提供环境变量DATA_SOURCE_NAME,注意,pod运行起来后,需要保证DATA_SOURCE_NAME的账号有数据库的读写权限。否则权限问题会导致无法获取数据。
进入pod查看端口3306/9104是否监听正常:
部署完mysql实例以及mysqld-exporter后,需要在prometheus的配置文件中增加相应的job。因为容器内POD IP是可变的,为了保证连接的持续可靠性,这里为该deployment创建了一个svc,通过svc的cluster IP与prometheus进行绑定,这样就基本不用担心POD IP变化了。
首先创建svc,捆绑2个服务端口:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21apiVersion: v1
kind: Service
metadata:
labels:
app: mydbtm
name: mydbtm
namespace: default
spec:
ports:
- port: 3306
protocol: TCP
targetPort: 3306
name: mysql
- port: 9104
protocol: TCP
targetPort: 9104
name: mysql-exporter
selector:
app: mydbtm
sessionAffinity: None
type: ClusterIP
kubectl get svc 获取刚创建的svc 的cluster IP,绑定至prometheus的confimap:
在prometheus-configmap.yaml下添加一个job,targets对应的列表内填写刚获取到的cluster IP和9104端口,后续增加实例可直接在列表中添加元素:1
2
3
4
5
6
7
8
9
10
11- job_name: 'mysql performance'
scrape_interval: 1m
static_configs:
- targets:
['10.102.20.179:9104']
params:
collect[]:
- global_status
- perf_schema.tableiowaits
- perf_schema.indexiowaits
- perf_schema.tablelocks
更新配置文件后滚动更新pod加载配置文件:1
kubectl patch deployment prometheus --patch '{"spec": {"template": {"metadata": {"annotations": {"update-time": "2018-06-25 17:50" }}}}}' -n kube-system
查看prometheus的target,可以看到mysql-exporter已经up了,如果有异常,检查pod志:
打开grafana查看mysql模板里的监控图: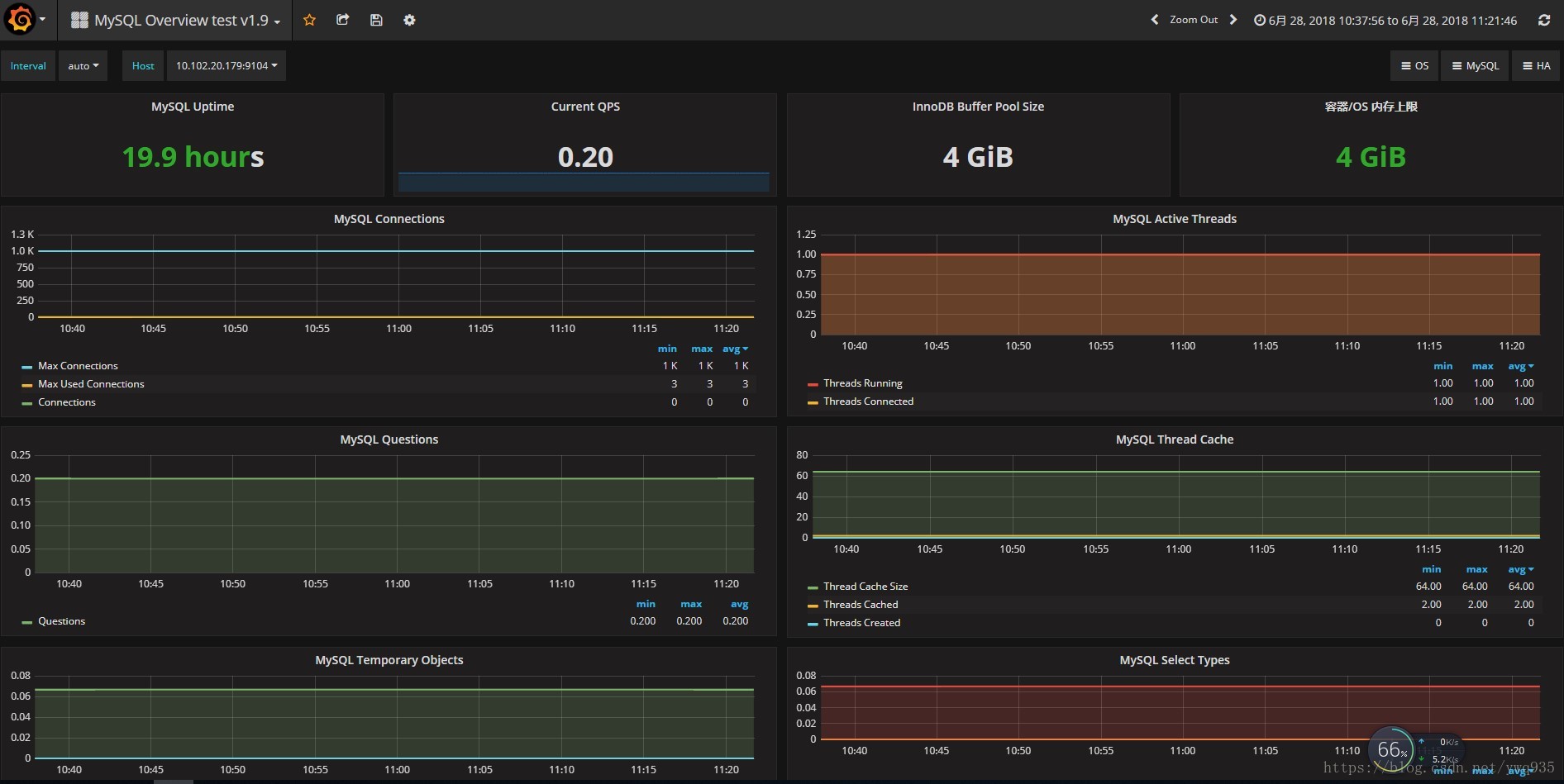
服务发现
在k8s环境中,部署的应用可能是海量的,如果像上方一样手动在static_configs.targets中增加对象,然后再触发prometheus实例的更新,未免显得太过麻烦和笨重,好在promethues提供SD(service discovery)功能,支持基于k8s的自动发现服务,可以自动发现k8s的node/service/pod/endpoints/ingress这些类型的资源。
其实在第一部分部署时,已经指定了kubernetes-service的target job,但是可以看到在web /target 路径页面上没有看到任何相关的job,连kubernetes-service的标题都没有:
在查阅了官方文档后,发现其中的说明并不详尽,没有具体的配置样例,网上关于此类场景的文章也没有找到,为此,特意去github上提交了issue向项目member请教,最后得知了不生效的原因为标签不匹配。
github issue链接:https://github.com/prometheus/prometheus/issues/4326
官方文档配置说明链接:prometheus配置
作出如下修改后,配置生效,web上可见:
1.job:
1 | - job_name: 'kube_svc_mysql-exporter' |
svc样例:
1 | apiVersion: v1 |
更新configmap以及prometheus实例后,即可在web /targets页面中查看到自动发现的包含mysql-exporter的svc,通过其集群FQDN域名+9104端口获取mysql-exporter metrics,实现自动发现。其他的各种应用,也可以类似定制。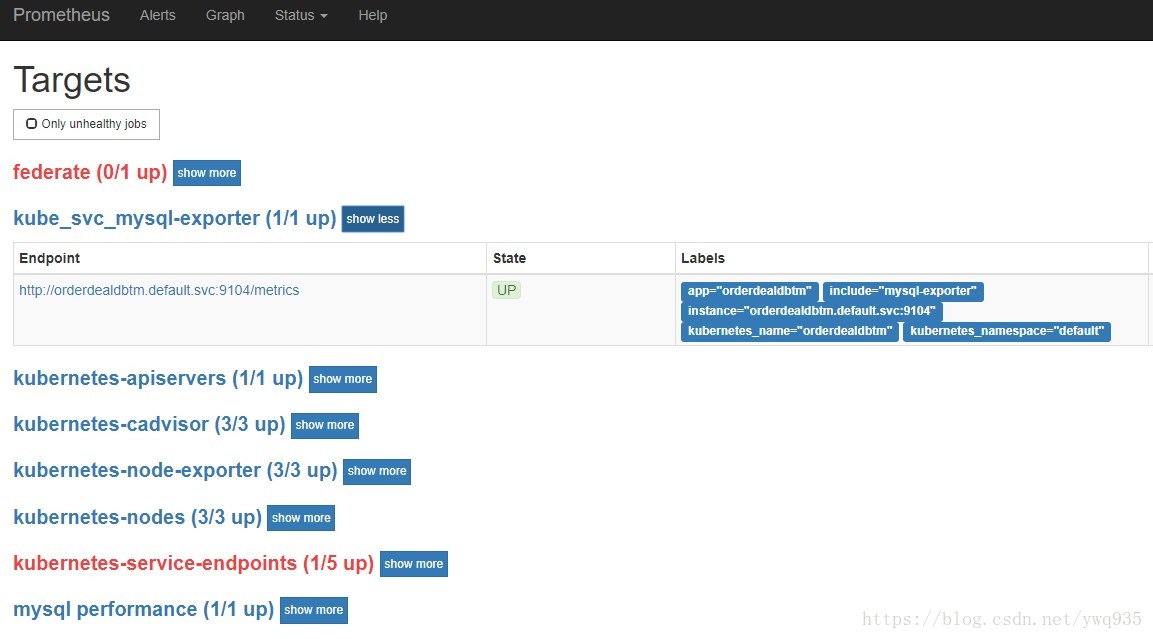
监控项
经过这几天的验证,整理了一些基础的监控项表达式,根据exporter进行了分类,当然这还不够,需要根据环境持续补充,调整.注意,metric的名称在不同的版本有些许不同,我们的环境中有两套prometheus,其中一套对应的exporter版本较低,注意点已注释出:
1 | targets: |
根据上方的监控项expr,整理出如下rules规则模板:
1 | rules.yml: | |
将这些规则更新进prometheus的configmap中,重新apply config,更新prometheus,查看prometheus的告警页面,可以查看多项告警选项,则配置成功。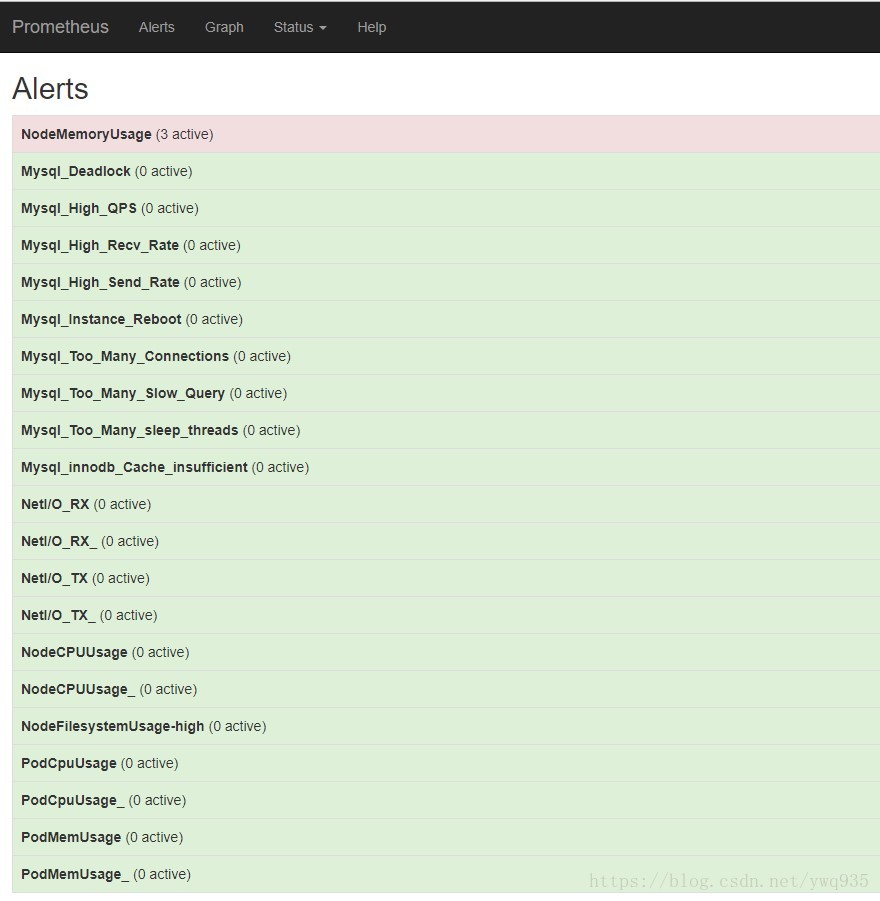
联邦
prometheus 2.0以上版本的新特性,联邦机制,支持从其他的prometheus扩展合并数据,比较类似zabbix的server端与proxy端,适用于跨集群/机房使用,但不同的是prometheus联邦配置非常简单,简单的增加job指定其他prometheus实例服务IP端口,即可获取数据。我们的环境中有两套集群,两个prometheus server实例,在prometheus的configmap配置增加一个如下job配置即可合并数据统一展示:
1 | - job_name: 'federate' |
更新配置,更新prometheus pod,重新打开grafana的集群监控模板页面,可以看到数据已经进行了整合:
整合前: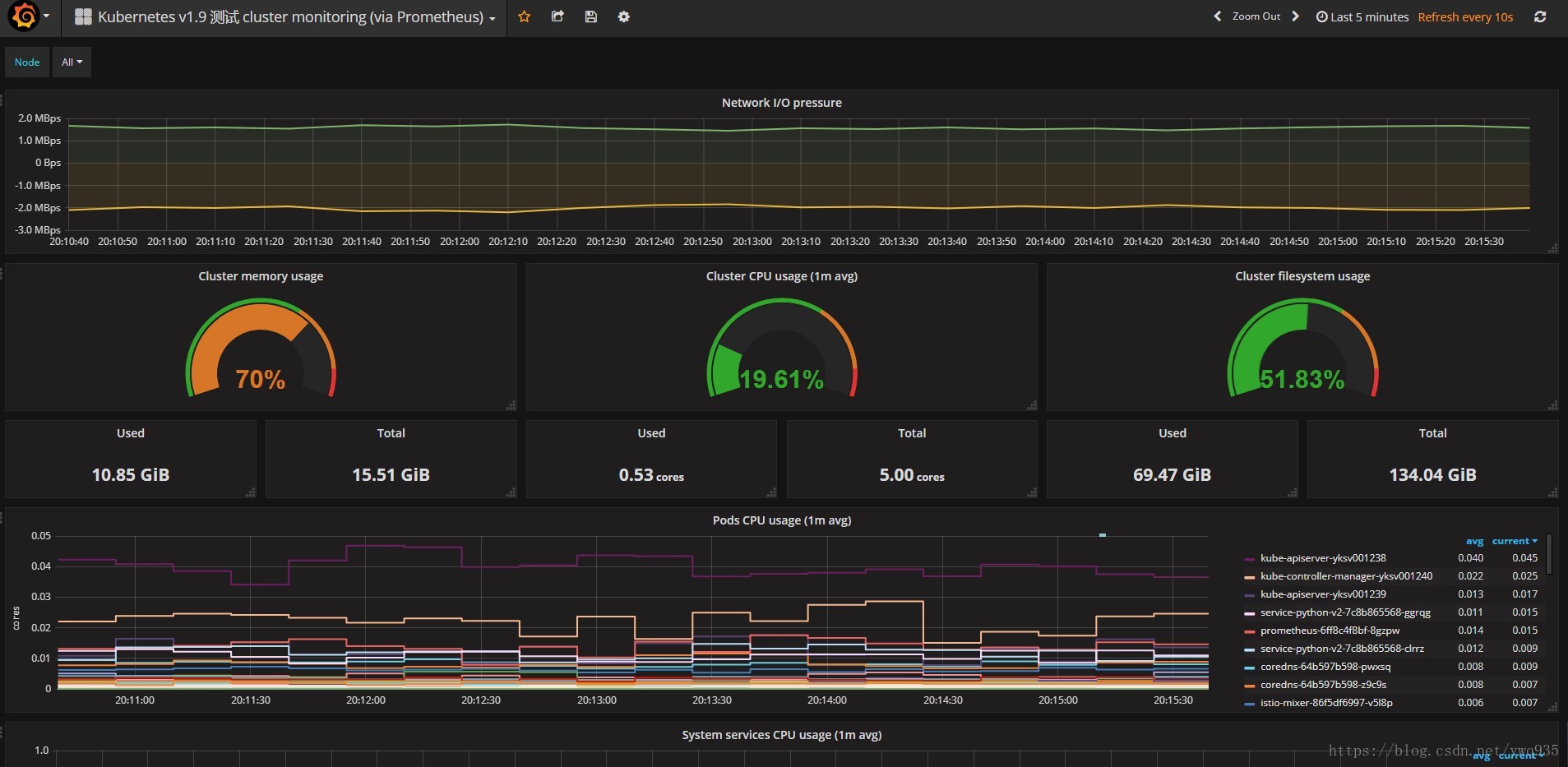
整合后:
Relabel
Relabel机制可以在Prometheus采集数据存入TSDB之前,通过Target实例的Metadata信息,动态地为Label赋值,可以是metadata中的label,也可以赋值给新label。除此之外,还能根据Target实例的Metadata信息选择是否采集或者忽略该Target实例。
例如这里自定义了如下target:
1 | - job_name: 'kubernetes-cadvisor' |
在web上查看target的原始标签: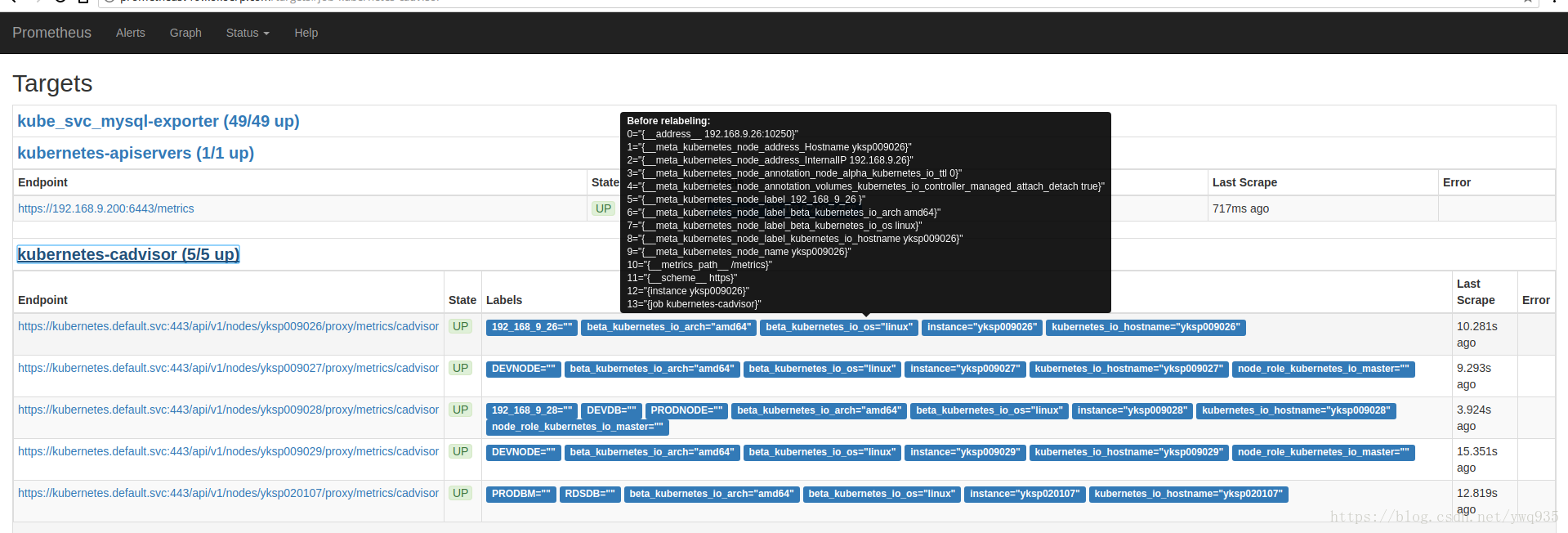
可以看到instance标签的值为主机名,鼠标悬停展开的黑色框中的标签为metadata标签,form表单里的标签是放入TSDB最终展示的标签
下面给这段配置增加一个自定义标签:
1 | - job_name: 'kubernetes-cadvisor' |
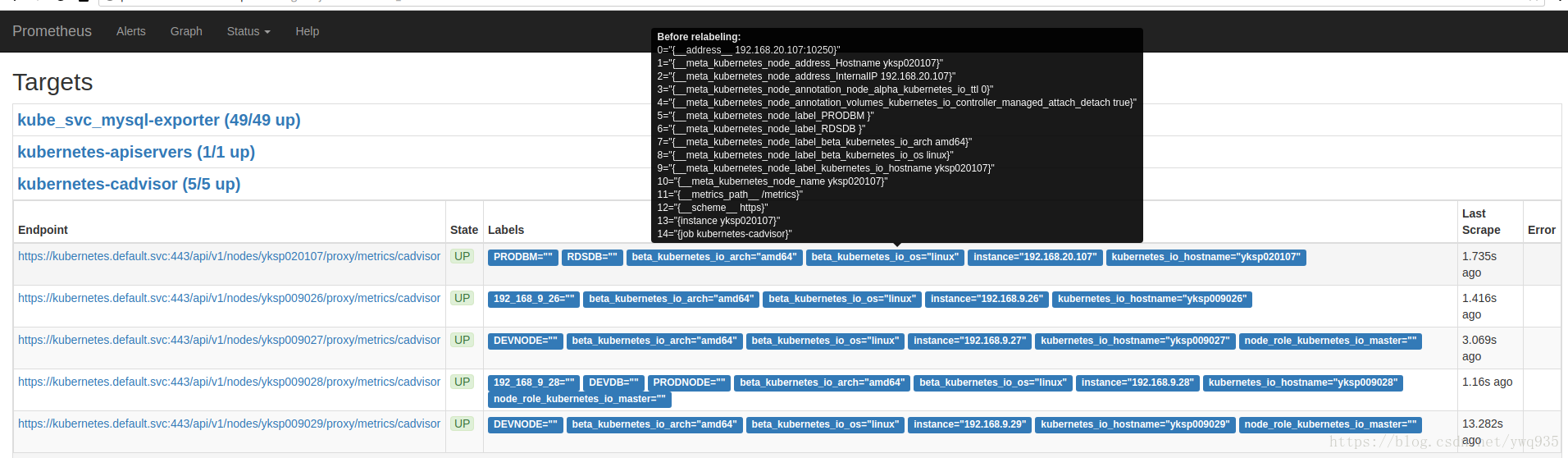
可以看到instance标签的值变成了host的IP地址
relabel配置解析:
1 | source_labels: [__address__] #值的来源标签(metadata),__address__是标签名 |
通过relabel,可以做一些自定义过滤规则,实现特殊的需求订制
配置热更新
监控配置项调整是非常常见的操作,如果每次调整配置后,都需要重建pod,过程还是比较繁琐漫长的,好在prometheus提供热重载的api,访问方式为:
1 | curl -X POST http://${IP/DOMAIN}/-/reload |
总结:
以上就是在上一篇的基础上对prometheus适应生产环境做的一些扩展,当然,需要做的监控项、应用还很多,配置文件、修改后的grafana模板文件随后打包附上,欢迎交流讨论,一起扩展。

