P4-Node优先级算法
前言
在上一篇文档中,我们过了一遍node筛选算法:
按调度规则设计,对筛选出的node,选择优先级最高的作为最终的fit node。那么本篇承接上一篇,进入下一步,看一看node优先级排序的过程。
Tips: 本篇篇幅较长,因调度优选算法较为复杂,但请耐心结合本篇阅读源码,多看几次,一定会有收获。
正文
1. 优先级函数
1.1 优先级函数入口
同上一篇,回到pkg/scheduler/core/generic_scheduler.go中的Schedule()函数,pkg/scheduler/core/generic_scheduler.go:184:
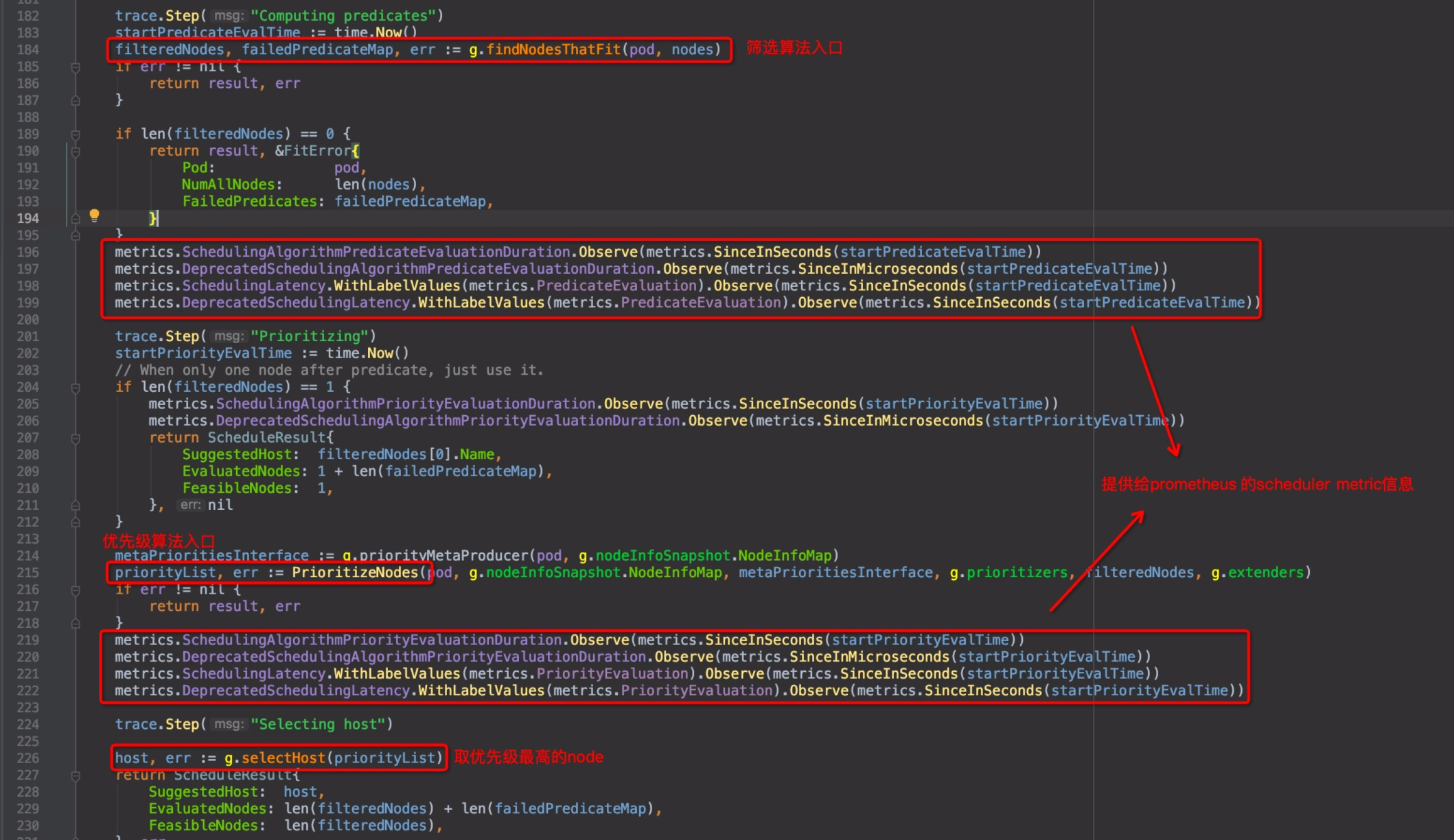
截图中有几处标注,metric相关的几行,是收集metric信息,用以提供给prometheus使用的,kubernetes的几个核心组件都有这个功能,以后如果读prometheus的源码,这个单独拎出来再讲。直接进入优先级函数PrioritizeNodes()内部pkg/scheduler/core/generic_scheduler.go:215
1.2 优先级函数概括说明
pkg/scheduler/core/generic_scheduler.go:645 PrioritizeNodes(),代码块较长,就不贴了.
在此函数上方的注释可以得知,这个函数的工作逻辑:
1.列出所有的优先级计算维度的方法,每个维度的方法返回该维度的得分,每个维度都有内部定义的weight权重,以及得分score,score取值范围在[0-10之间],该维度的最终得分为 (score * weight),得分越高越好
2.列出所有参与运算的node
3.循环对每一个node分别进行1中所有维度方法项计算,最后将该node的所有计算维度得分汇总
这里有一个重要的结构体始终贯穿整个函数栈,特别指出:
1 | // HostPriority represents the priority of scheduling to a particular host, higher priority is better. |
两个重要变量
1 | // pkg/scheduler/core/generic_scheduler.go:678 |
1.3 优先级函数分段说明
1.3.1 Function(DEPRECATED)
pkg/scheduler/core/generic_scheduler.go:682
1 |
|
注释中说明这种直接计算方法(priorityConfigs[i].Function)是传统模式,已经DEPRECATED掉了,当前版本实际上只有一个维度(pod亲和性)采取了这种方法,取而代之的是Map-Reduce模式的计算方法,参见后方。Function运算的方式,随后会以pod亲和性这个维度的实例代码来说明。
1.3.2 Map-Reduce Function
pkg/scheduler/core/generic_scheduler.go:698
1 | workqueue.ParallelizeUntil(context.TODO(), 16, len(nodes), func(index int) { |
这里可以看出,若该维度未直接指定priorityConfigs[i].Function,则采取Map-Reduce模式.
1 | 引申:Map-Reduce是大数据里的思想,简单来说Map函数是对一组元素集上的每一个元素进行高度并行的运算,得到与元素 |
这里再次出现了上一篇中特别提到的workqueue.ParallelizeUntil()并行运算控制方法,同样以node为粒度,运行Map函数;而下方并行度不高的Reduce函数,则使用的sync模块才实现并发控制。符合Map-Reduce的思想。
没接触过Map-Reduce,但先不要被吓住,这里只是利用了这个思想,数据量并没有复杂到要拆分给多台机器分布式运算的级别。随后举一个使用Map-Reduce计算方法的维度的实例代码来说明。
2. 优先级计算维度
2.1 默认注册的计算维度
通过上面的内容,对优先级算法有了一个模糊的认知:统计节点的各计算维度得分的总和,分数越高优先级越高。那么默认的优先级计算维度分别有哪些呢?在前面的scheduler-框架篇中有讲过,调度算法全部位于pkg/scheduler/algorithm目录中,而pkg/scheduler/algorithmprovider内提供以工厂模式创建调度算法相关元素的方法,所以,我们直接来到pkg/scheduler/algorithmprovider/defaults/register_priorities.go文件内,所有默认的优先级计算维度的算法都在这里注册,篇幅有限,随便列举其中几个:
1 | factory.RegisterPriorityFunction2(priorities.EqualPriority, core.EqualPriorityMap, nil, 1) |
如果仔细看代码里的注释可以发现,个别factory函数虽然已经将计算维度注册,但实际上默认并没有启用它,例如ServiceSpreadingPriority这一项中的注释表明,它已经相当大程度被SelectorSpreadPriority取代了,保留它是为了兼容此前的版本。那么默认使用的计算维度有哪些呢?
2.2 默认使用的计算维度
默认使用的计算维度,在这个地方声明:
pkg/scheduler/algorithmprovider/defaults/defaults.go:108
1 | func defaultPriorities() sets.String { |
2.3 新旧两种计算方式
在注册的每一个计算维度,都有专属的维度描述关键字,即factory方法的第一个参数(str类型)。不难发现,这里的每一个关键字,pkg/scheduler/algorithm/priorities目录内都有与其对应的文件,图中圈出了几个例子(灵魂画笔请原谅):
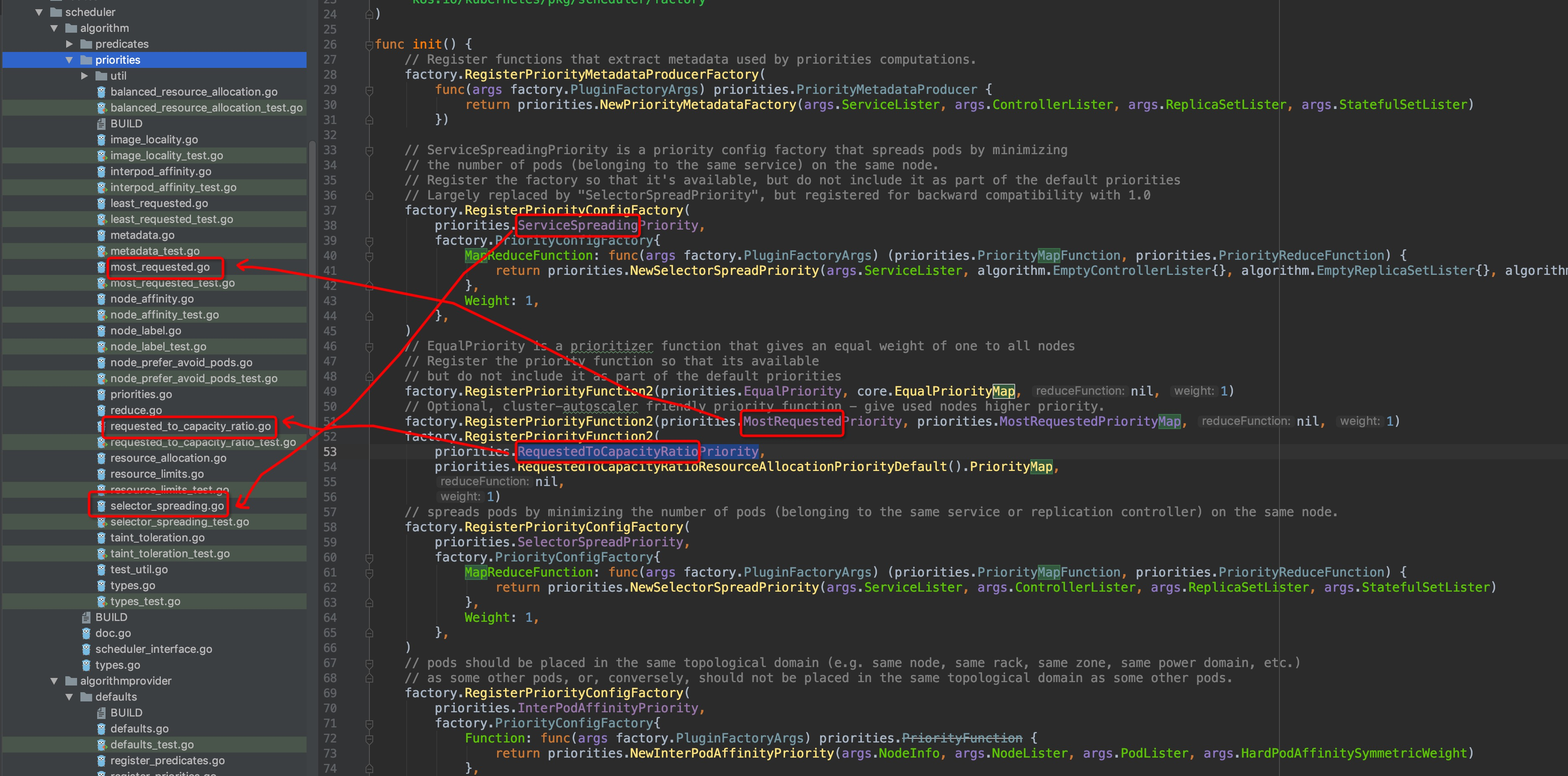
显而易见,维度计算的内容就在这些文件中,可以自行通过编辑器的跳转功能逐级查看进行验证.
通过这是factory方法可以看出,所有维度,默认的注册权重都是1,除了NodePreferAvoidPodsPriority这一项之外,它的weight值是10000,这一项是为了避免pod调度到node上,我们找到文件查看该方法的注释:
pkg/scheduler/algorithm/priorities/node_prefer_avoid_pods.go:31
1 | // CalculateNodePreferAvoidPodsPriorityMap priorities nodes according to the node annotation |
得知node可以通过annotation添加scheduler.alpha.kubernetes.io/preferAvoidPods指定来避免指定的pod调度到本身之上,因此此项优先级超高覆盖过其他的各计算维度。
如果ctrl + F 过滤一下map关键字,你会发现,仅有InterPodAffinityPriority这一项是没有map关键字的:
1 | // pods should be placed in the same topological domain (e.g. same node, same rack, same zone, same power domain, etc.) |
这也印证了前面说的当前仅剩pod亲和性这一个维度在使用传统的Function,虽然已经被DEPRECATED掉了,传统的Function是直接计算出结果,Map-Reduce是将这个过程解耦拆成了两个步骤,且我们可以看到所有的factory函数,很多形参reduceFunction接收到的实参实际是是nil:
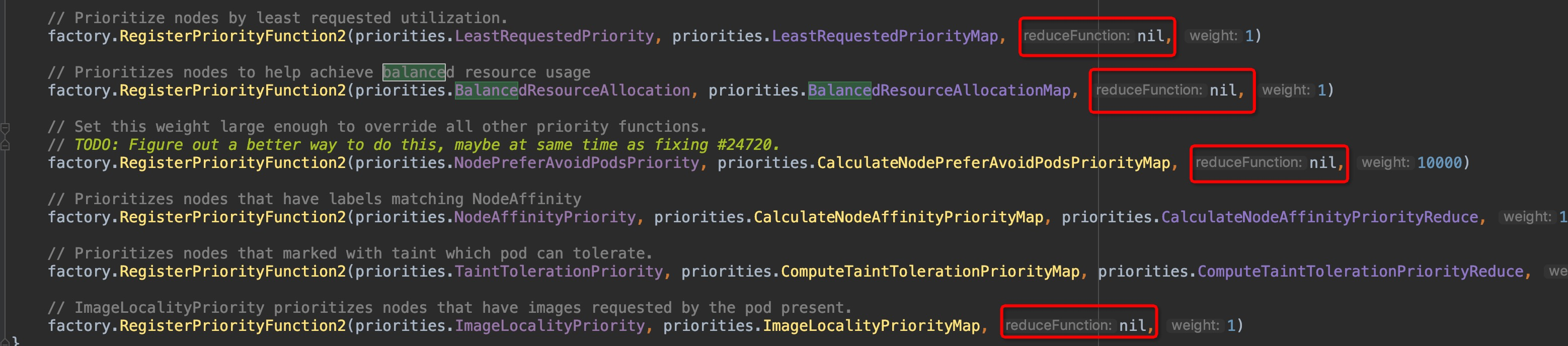
这就说明这些维度的计算工作在map函数里面已经执行完成了,不需要再执行reduce函数了。因此,传统的Function的计算过程同样值得参考,那么首先就来看看InterPodAffinityPriority维度是怎么计算的吧!
3. 传统计算Function
3.1 InterPodAffinityPriority
看代码之前,先来看一个标准的PodAffinity配置示例:
PodAffinity示例:
1 | apiVersion: v1 |
yaml中的申明意图是: pod-a亲近pod-b,疏远pod-c,所以在这项计算维度里,如果node上运行着pod-b ,则该node加分,如果该node上运行着pod-c,则node减分。
来看代码,仔细读代码,你会发现示例中的几个层级的key: PreferredDuringSchedulingIgnoredDuringExecution,podAffinityTerm,labelSelector,topologyKey在代码中都会出现:
pkg/scheduler/algorithm/priorities/interpod_affinity.go:119:
1 | func (ipa *InterPodAffinity) CalculateInterPodAffinityPriority(pod *v1.Pod, nodeNameToInfo map[string]*schedulernodeinfo.NodeInfo, nodes []*v1.Node) (schedulerapi.HostPriorityList, error) { |
上面代码中的注释已经将CalculateInterPodAffinityPriority这个函数的工作模式介绍的比较清晰了,那么再看一看计分函数processTerm():
pkg/scheduler/algorithm/priorities/interpod_affinity.go:107 –> pkg/scheduler/algorithm/priorities/interpod_affinity.go:86
1 | func (p *podAffinityPriorityMap) processTerm(term *v1.PodAffinityTerm, podDefiningAffinityTerm, podToCheck *v1.Pod, fixedNode *v1.Node, weight float64) { |
podAffinityPriority这个维度的算法到此就明了了
4. Map-Reduce计算方法
在pkg/scheduler/algorithmprovider/defaults/register_priorities.go:26中的init()函数内,找出所有在注册且默认被使用的,同时包含map方法和reduce方法的factory函数,一共有3个,我们挑其中之一为例作启发,其余的就不写在文章里了,可以自行阅读:
1 | // pkg/scheduler/algorithmprovider/defaults/register_priorities.go:58 |
那就以第一个ServiceSpreadingPriority维度为例吧,名字直译为: 选择器均分优先级,注释中可以得知,这一项是为了保障属于同一个Service或replication controller的的pod,尽量分散开在不同的node里,保障高可用。
NewSelectorSpreadPriority()方法用来注册此维度的Map和Reduce函数,来看看其内容:
pkg/scheduler/algorithmprovider/defaults/register_priorities.go:62 NewSelectorSpreadPriority()—-> pkg/scheduler/algorithm/priorities/selector_spreading.go:45
1 | func NewSelectorSpreadPriority( |
注意这4个参数:serviceLister/replicaSetLister/statefulSetLister/controllerLister,与pod相关的四个上层抽象概念Service/RC/RS/StatefulSet都列出来了,返回的map函数是CalculateSpreadPriorityMap,reduce函数是CalculateSpreadPriorityReduce,分别看一看他们吧
4.1 Map函数
pkg/scheduler/algorithm/priorities/selector_spreading.go:66
1 | func (s *SelectorSpread) CalculateSpreadPriorityMap(pod *v1.Pod, meta interface{}, nodeInfo *schedulernodeinfo.NodeInfo) (schedulerapi.HostPriority, error) { |
继续看countMatchingPods函数:
pkg/scheduler/algorithm/priorities/selector_spreading.go:187:
1 | func countMatchingPods(namespace string, selectors []labels.Selector, nodeInfo *schedulernodeinfo.NodeInfo) int { |
这里的计算方式概括一下:
已知Service/RC/RS/StatefulSet这四种对pod进行管理的抽象高层级资源(后面统称高层级资源),选择器都是通过label来匹配pod的,因此,这里将待调度pod的高层级资源的selector选择器依次列出,与node上现运行的pod中的每一个进行依次比较,每出现一次待调度pod的selector,命中了某个现运行pod的标签的情况,则视为匹配成功,加1分,未命中则不加分(这里的分数越高代表匹配到的现运行pod数量越多,则最终优先级得分应该越低,待会儿在reduce函数里我们可以印证)。
举个例子:
- 假设待调度的为pod-a-1,node-a,node-b上现都运行有若干个pod
- node-a其中有1个pod-a-2与pod-a-1属于同一个Service,那么,node-a的count计数为1;
- node-b中没有pod被pod-a-1的selector命中,则node-b的count计数为0
- 计数越多,则对应的最终优先级得分应该越低,因此node-b的得分会比node-a高
map函数到这里就结束了,但这个计数显然还不能作为节点在此维度的最终得分,因此,下面还有reduce函数
4.1 Reduce函数
基于前面map函数得出的各node的匹配次数count计数,来展开reduce函数运算:
pkg/scheduler/algorithm/priorities/selector_spreading.go:99
1 | func (s *SelectorSpread) CalculateSpreadPriorityReduce(pod *v1.Pod, meta interface{}, nodeNameToInfo map[string]*schedulernodeinfo.NodeInfo, result schedulerapi.HostPriorityList) error { |
不难发现,这里的Reduce函数统计得分的方式,与传统Function最后一步统计最终得分,步骤可以说是一致的:
1 | // PodAffinityPriority统计最终得分 |
只不过这里是使用Map-Reduce风格思想将其步骤解耦为了两步。Reduce函数介绍到此结束
总结
优先级算法相对而言比predicate断言算法要复杂一些,并且在当前版本的维度计算中存在传统Function函数与Map-Reduce风格函数混用的现象,一定程度上提高了阅读的难度,但相信仔细重复阅读代码,还是不难理解的,毕竟数据量还未到达大数据的级别,只是利用了其映射归纳的思想,解耦的同时提高一定的并发性能。
下一篇讲什么呢?我再研究研究,have fun!

