P3-Controller分类与Deployment Controller
前言
Controller部分的第一篇文章中,我们从cobra启动命令入口开始,进入到了多实例leader选举部分的代码,对leader选举流程做了详细地分析:
接着在第二篇中,文字和图解简单描述了controller是如何结合client-go模块中的informer工作的,为本篇及后面的几篇作铺垫:
Controller-P2-Controller与informer
那么本篇,就接着第一篇往下,继续看代码。
Controller的分类
启动
承接篇一,在cobra入口之下,controller的启动入口在这里:
cmd/kube-controller-manager/app/controllermanager.go:191
1 | run := func(ctx context.Context) {} |
==> cmd/kube-controller-manager/app/controllermanager.go:217,重点是这里的NewControllerInitializers函数。
1 | if err := StartControllers(controllerContext, saTokenControllerInitFunc, NewControllerInitializers(controllerContext.LoopMode), unsecuredMux); err != nil { |
==> cmd/kube-controller-manager/app/controllermanager.go:343
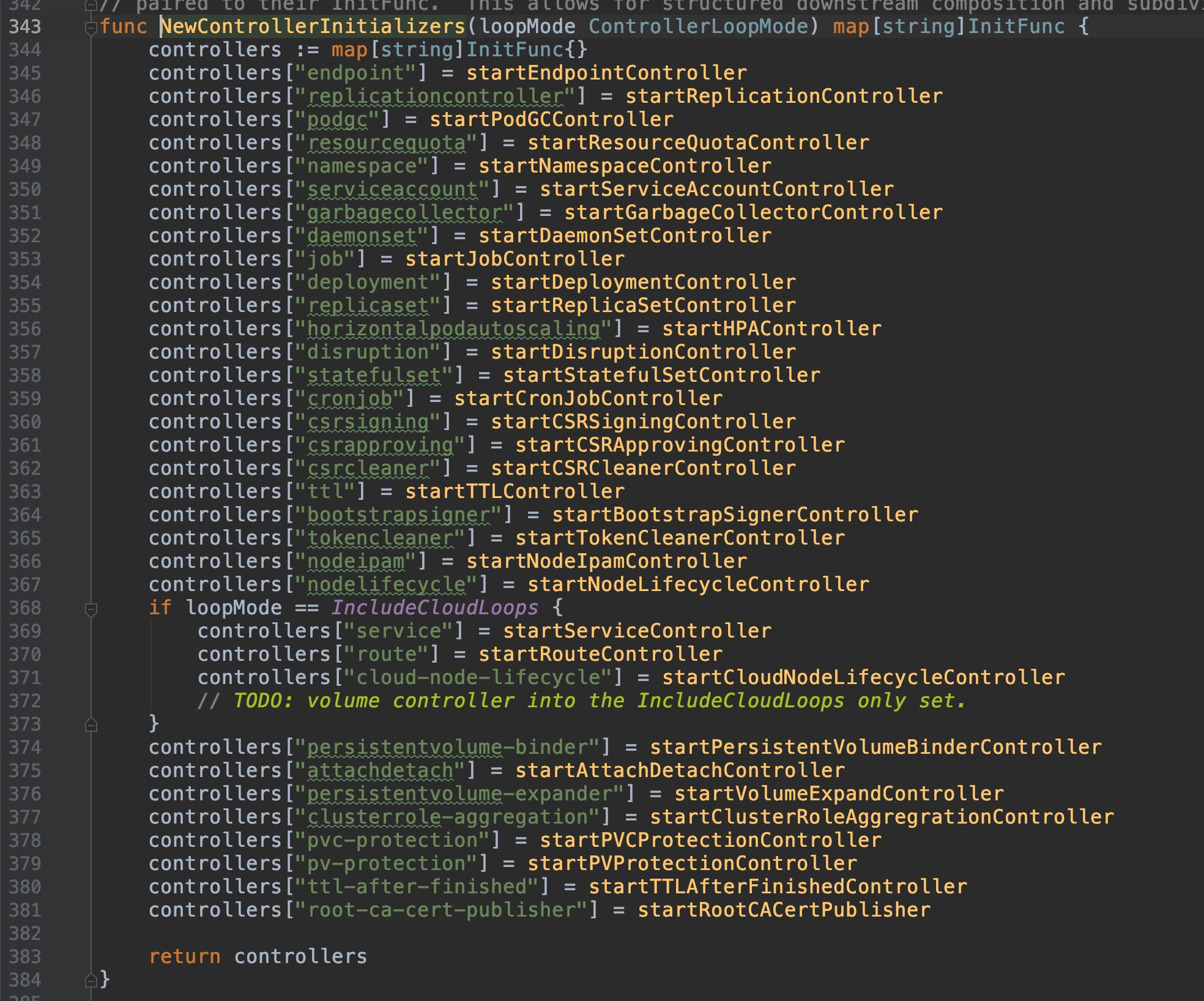
可以看到,controller会对不同的资源,分别初始化相应的controller,包含我们常见的deployment、statefulset、endpoint、pvc等等资源,controller种类有多达30余个。因此,在controller整个章节中,不会对它们逐一分析,只会抽取几个常见有代表性地进行深入,本篇就来看看deployment controller吧。
Deployment Controller
初始化
cmd/kube-controller-manager/app/controllermanager.go:354
1 | controllers["deployment"] = startDeploymentController |
==> cmd/kube-controller-manager/app/apps.go:82
1 | func startDeploymentController(ctx ControllerContext) (http.Handler, bool, error) { |
dc.Run()函数,第一个参数是worker的数量,默认值是5个,在这里定义的:pkg/controller/apis/config/v1alpha1/defaults.go:48,第二个参数是空结构体,让go协程接收异常停止的信号。
==> pkg/controller/deployment/deployment_controller.go:148
1 | // Run begins watching and syncing. |
controller.WaitForCacheSync函数是用来检测各个informer是否本地缓存已经同步完毕的函数,返回值是bool类型。前面第二章讲到过,informer为了加速和减轻apiserver的负担,设计了local storage缓存,因此这里做了一步缓存是否已同步的检测。
默认是5个worker,每个worker,调用wait.Until()方法,每间隔1s,循环执行dc.worker函数,运行deployment controller的工作逻辑。wait.Until()这个循环调用的计时器函数还是挺有意思的,展开看下。
wait.Until循环计时器函数
pkg/controller/deployment/deployment_controller.go:160
==> vendor/k8s.io/apimachinery/pkg/util/wait/wait.go:88
==>vendor/k8s.io/apimachinery/pkg/util/wait/wait.go:130
1 | func JitterUntil(f func(), period time.Duration, jitterFactor float64, sliding bool, stopCh <-chan struct{}) { |
resetOrReuseTimer函数:
1 | func resetOrReuseTimer(t *time.Timer, d time.Duration, sawTimeout bool) *time.Timer { |
概括一下,这个函数是对timer模块的一个再封装,重复利用timer计时器,来每秒执行一次dc.worker().
dc.worker函数
pkg/controller/deployment/deployment_controller.go:460
==> pkg/controller/deployment/deployment_controller.go:464
1 | func (dc *DeploymentController) processNextWorkItem() bool { |
Deployment controller 的worker函数就是不断地调用processNextWorkItem函数,processNextWorkItem函数是从work queue中获取待处理的对象(第二篇中informer图解中的第7-第8步),如果存在,那么执行相应后续的增删改查逻辑,如果不存在,那么就退出。
其中dc.queue.Get()接口方法的实现在这里:
vendor/k8s.io/client-go/util/workqueue/queue.go:140
1 | func (q *Type) Get() (item interface{}, shutdown bool) { |
其中的dc.syncHandler()方法在这里:
pkg/controller/deployment/deployment_controller.go:135
1 | dc.syncHandler = dc.syncDeployment |
==> pkg/controller/deployment/deployment_controller.go:560
所有的增删改(滚动更新)查操作,全部都在这个函数内部处理。
1 | func (dc *DeploymentController) syncDeployment(key string) error { |
暂停和扩(缩)容(/删除)
dc.sync方法这里出现了两次,分别在pause状态和scaling状态调用,比较关键,分析一下sync方法的内容。
pkg/controller/deployment/sync.go:48
1 | func (dc *DeploymentController) sync(d *apps.Deployment, rsList []*apps.ReplicaSet) error { |
来看看dc.scale()方法:
pkg/controller/deployment/sync.go:289
1 | func (dc *DeploymentController) scale(deployment *apps.Deployment, newRS *apps.ReplicaSet, oldRSs []*apps.ReplicaSet) error { |
syncDeploymentStatus函数
在完成rs的scale和pause状态的逻辑处理后,deployment的状态也需要与最新的rs同步,因此这个函数就是用来同步deployment的状态的。
1 | func (dc *DeploymentController) syncDeploymentStatus(allRSs []*apps.ReplicaSet, newRS *apps.ReplicaSet, d *apps.Deployment) error { |
这个函数主要用来更新deployment的status字段的内容,例如版本、副本数、可用副本数、更新副本数等等。
整个扩容的过程涉及所有rs的操作,可能很容易混淆,但其实只要记住在99%的情况下,deployment只有一个活跃状态的rs,即newRS,大部分操作都是针对这个newRS做的,那么上面的过程就容易理解很多了。
滚动更新
Deployment更新策略分为滚动更新和一次性更新,更新方式其实都是类似,只是一个是分批式,一个是全量式,这里看下滚动更新的代码。
deployment 的spec字段内的内容一旦发生变化,就会触发rs的更新,生成新版本的rs,并且基于新rs进行副本扩容,旧版本的rs则会缩容。
pkg/controller/deployment/deployment_controller.go:644
==> pkg/controller/deployment/rolling.go:31
1 | func (dc *DeploymentController) rolloutRolling(d *apps.Deployment, rsList []*apps.ReplicaSet) error { |
reconcileNewReplicaSet函数:
这个函数返回bool值,即是否应该扩容newRS的bool值
1 | func (dc *DeploymentController) reconcileNewReplicaSet(allRSs []*apps.ReplicaSet, newRS *apps.ReplicaSet, deployment *apps.Deployment) (bool, error) { |
NewRSNewReplicas函数:
计算newRS此时应该有的副本数量的函数
1 | func NewRSNewReplicas(deployment *apps.Deployment, allRSs []*apps.ReplicaSet, newRS *apps.ReplicaSet) (int32, error) { |
reconcileOldReplicaSets函数
这个函数返回bool值,即是否应该缩容oldRSs的bool值
1 | func (dc *DeploymentController) reconcileOldReplicaSets(allRSs []*apps.ReplicaSet, oldRSs []*apps.ReplicaSet, newRS *apps.ReplicaSet, deployment *apps.Deployment) (bool, error) { |
中间的英文注释里的举例说明非常详细,可以看一下注释。
syncRolloutStatus函数
这个函数主要用于更新deployment的status字段和其中的condition字段。
1 | func (dc *DeploymentController) syncRolloutStatus(allRSs []*apps.ReplicaSet, newRS *apps.ReplicaSet, d *apps.Deployment) error { |
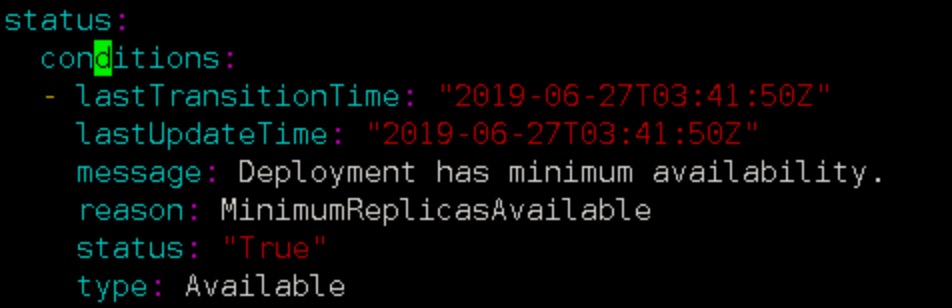
DeploymentCondition在这里面反复出现,便于理解,参照一个正常状态的deployment condition样例:
总结
滚动更新过程中主要是通过调用reconcileNewReplicaSet函数对 newRS 扩容,调用 reconcileOldReplicaSets函数 对 oldRSs缩容,按照 maxSurge 和 maxUnavailable 的约束,计时器间隔1s反复执行、收敛、修正,最终达到期望状态,完成更新。
总结
Deployment的回滚、扩(缩)容、暂停、更新等操作,主要是通过修改rs来完成的。其中,rs的版本控制、replicas数量控制是其最核心也是难以理解的地方,但是只要记住99%的时间里deployment对应的活跃的rs只有一个,只有更新时才会出现2个rs,极少数情况下(短时间重复更新)才会出现2个以上的rs,对于上面源码的理解就会容易许多。
另外,从上面这么多步骤的拆解也可以发现,deployment的更新实际基本不涉及对pod的直接操作,因此,本章后续的章节会分析一下replicaSet controller是怎么和pod进行管理交互的。

