P3-Controller分类与Deployment Controller
前言
Controller部分的第一篇文章中,我们从cobra启动命令入口开始,进入到了多实例leader选举部分的代码,对leader选举流程做了详细地分析:
接着在第二篇中,文字和图解简单描述了controller是如何结合client-go模块中的informer工作的,为本篇及后面的几篇作铺垫:
Controller-P2-Controller与informer
那么本篇,就接着第一篇往下,继续看代码。
Controller的分类
启动
承接篇一,在cobra入口之下,controller的启动入口在这里:
cmd/kube-controller-manager/app/controllermanager.go:191
run := func(ctx context.Context) {}
==> cmd/kube-controller-manager/app/controllermanager.go:217,重点是这里的NewControllerInitializers函数。
if err := StartControllers(controllerContext, saTokenControllerInitFunc, NewControllerInitializers(controllerContext.LoopMode), unsecuredMux); err != nil {
klog.Fatalf("error starting controllers: %v", err)
}
==> cmd/kube-controller-manager/app/controllermanager.go:343
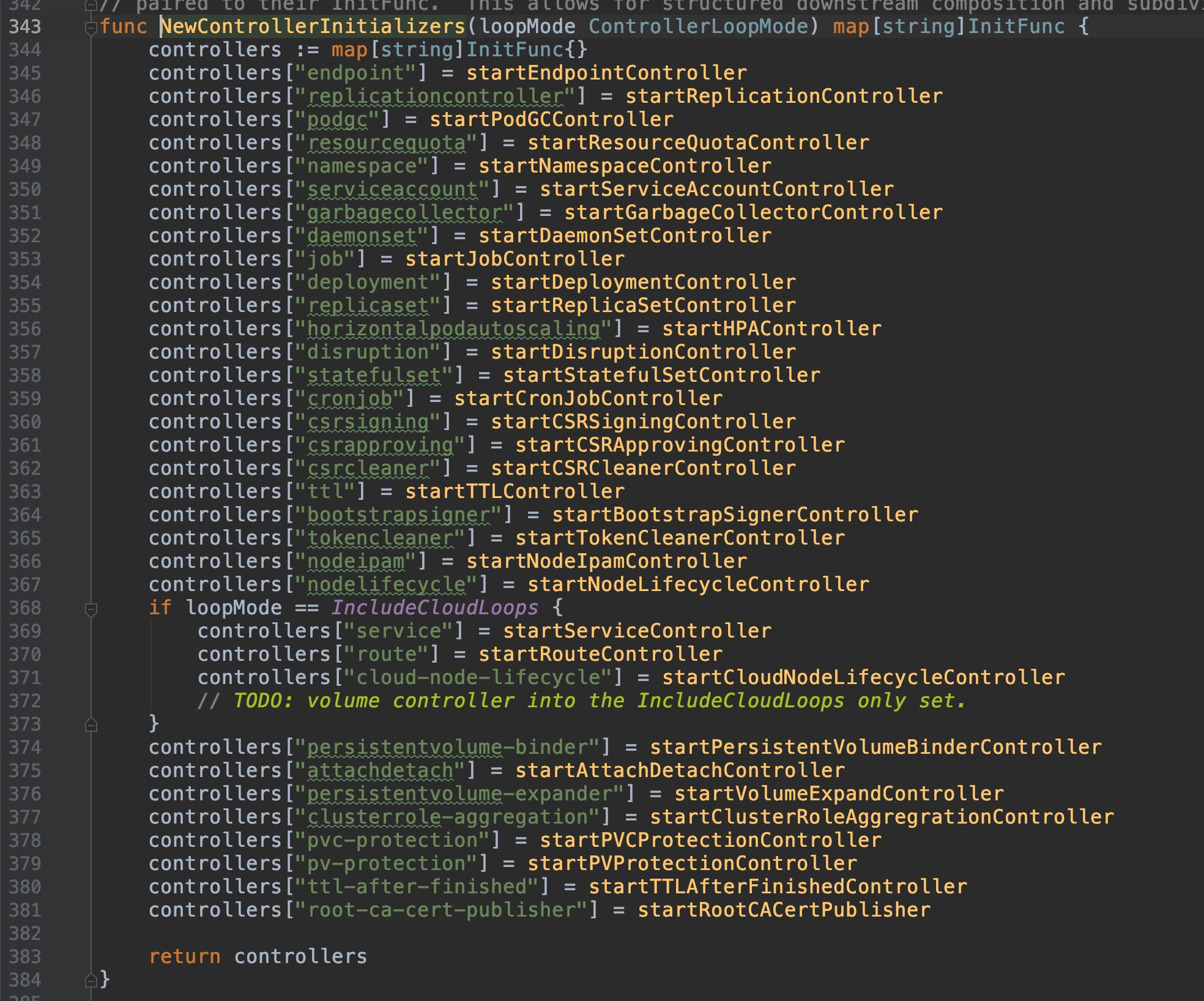
可以看到,controller会对不同的资源,分别初始化相应的controller,包含我们常见的deployment、statefulset、endpoint、pvc等等资源,controller种类有多达30余个。因此,在controller整个章节中,不会对它们逐一分析,只会抽取几个常见有代表性地进行深入,本篇就来看看deployment controller吧。
Deployment Controller
初始化
cmd/kube-controller-manager/app/controllermanager.go:354
controllers["deployment"] = startDeploymentController
==> cmd/kube-controller-manager/app/apps.go:82
func startDeploymentController(ctx ControllerContext) (http.Handler, bool, error) {
if !ctx.AvailableResources[schema.GroupVersionResource{Group: "apps", Version: "v1", Resource: "deployments"}] {
return nil, false, nil
}
dc, err := deployment.NewDeploymentController(
// deployment主要关注这3个资源: Deployment/ReplicaSet/Pod,deployment通过replicaSet来管理Pod
// 这3个函数会返回相应资源的informer
ctx.InformerFactory.Apps().V1().Deployments(),
ctx.InformerFactory.Apps().V1().ReplicaSets(),
ctx.InformerFactory.Core().V1().Pods(),
ctx.ClientBuilder.ClientOrDie("deployment-controller"),
)
if err != nil {
return nil, true, fmt.Errorf("error creating Deployment controller: %v", err)
// deployment controller 运行函数
go dc.Run(int(ctx.ComponentConfig.DeploymentController.ConcurrentDeploymentSyncs), ctx.Stop)
return nil, true, nil
}
dc.Run()函数,第一个参数是worker的数量,默认值是5个,在这里定义的:pkg/controller/apis/config/v1alpha1/defaults.go:48,第二个参数是空结构体,让go协程接收异常停止的信号。
==> pkg/controller/deployment/deployment_controller.go:148
// Run begins watching and syncing.
func (dc *DeploymentController) Run(workers int, stopCh <-chan struct{}) {
defer utilruntime.HandleCrash()
defer dc.queue.ShutDown()
klog.Infof("Starting deployment controller")
defer klog.Infof("Shutting down deployment controller")
// 判断各个informer的缓存是否已经同步完毕的函数
if !controller.WaitForCacheSync("deployment", stopCh, dc.dListerSynced, dc.rsListerSynced, dc.podListerSynced) {
return
}
// 启动多个worker开始工作
for i := 0; i < workers; i++ {
go wait.Until(dc.worker, time.Second, stopCh)
}
<-stopCh
}
controller.WaitForCacheSync函数是用来检测各个informer是否本地缓存已经同步完毕的函数,返回值是bool类型。前面第二章讲到过,informer为了加速和减轻apiserver的负担,设计了local storage缓存,因此这里做了一步缓存是否已同步的检测。
默认是5个worker,每个worker,调用wait.Until()方法,每间隔1s,循环执行dc.worker函数,运行deployment controller的工作逻辑。wait.Until()这个循环调用的计时器函数还是挺有意思的,展开看下。
wait.Until循环计时器函数
pkg/controller/deployment/deployment_controller.go:160
==> vendor/k8s.io/apimachinery/pkg/util/wait/wait.go:88
==>vendor/k8s.io/apimachinery/pkg/util/wait/wait.go:130
func JitterUntil(f func(), period time.Duration, jitterFactor float64, sliding bool, stopCh <-chan struct{}) {
var t *time.Timer
var sawTimeout bool
for {
select {
case <-stopCh:
return
default:
}
jitteredPeriod := period
if jitterFactor > 0.0 {
jitteredPeriod = Jitter(period, jitterFactor)
}
// sliding这个布尔值的意思是是否将执行函数f()的执行时间计入执行间隔时间内,如果为否,则在f执行前就开始计时,如果为是,则在f执行后再开始计时。
if !sliding {
t = resetOrReuseTimer(t, jitteredPeriod, sawTimeout)
}
func() {
defer runtime.HandleCrash()
f()
}()
if sliding {
t = resetOrReuseTimer(t, jitteredPeriod, sawTimeout)
}
// select 下各个分支的权重是公平的,因此,stop信号的处理,在循环开始之前和循环开始之后都分别判断了一次
select {
case <-stopCh:
return
// Timer.C是Timer结构体内部的一个channel,计时器在到达指定的时间后会往此channel发送一个事件,channel同时也可以被接收,来触发其他的逻辑。这里的逻辑是判断:如果f()执行超过计时器的超时时间,那么加一个超时的标记sawTimeout。
case <-t.C:
sawTimeout = true
}
}
}
resetOrReuseTimer函数:
func resetOrReuseTimer(t *time.Timer, d time.Duration, sawTimeout bool) *time.Timer {
if t == nil {
return time.NewTimer(d)
}
if !t.Stop() && !sawTimeout {
<-t.C
}
t.Reset(d)
return t
}
概括一下,这个函数是对timer模块的一个再封装,重复利用timer计时器,来每秒执行一次dc.worker().
dc.worker函数
pkg/controller/deployment/deployment_controller.go:460
==> pkg/controller/deployment/deployment_controller.go:464
func (dc *DeploymentController) processNextWorkItem() bool {
// 从队列头部取出对象
key, quit := dc.queue.Get()
if quit {
return false
}
defer dc.queue.Done(key)
// 处理对象
err := dc.syncHandler(key.(string))
dc.handleErr(err, key)
return true
}
Deployment controller 的worker函数就是不断地调用processNextWorkItem函数,processNextWorkItem函数是从work queue中获取待处理的对象(第二篇中informer图解中的第7-第8步),如果存在,那么执行相应后续的增删改查逻辑,如果不存在,那么就退出。
其中dc.queue.Get()接口方法的实现在这里:
vendor/k8s.io/client-go/util/workqueue/queue.go:140
func (q *Type) Get() (item interface{}, shutdown bool) {
q.cond.L.Lock()
defer q.cond.L.Unlock()
for len(q.queue) == 0 && !q.shuttingDown {
q.cond.Wait()
}
if len(q.queue) == 0 {
// We must be shutting down.
return nil, true
}
// 取出队列的队首
item, q.queue = q.queue[0], q.queue[1:]
q.metrics.get(item)
// 对象加入正在处理中map
q.processing.insert(item)
// dirty map去除对象(dirty map中保存的是等待处理的对象)
q.dirty.delete(item)
return item, false
}
其中的dc.syncHandler()方法在这里:
pkg/controller/deployment/deployment_controller.go:135
dc.syncHandler = dc.syncDeployment
==> pkg/controller/deployment/deployment_controller.go:560
所有的增删改(滚动更新)查操作,全部都在这个函数内部处理。
func (dc *DeploymentController) syncDeployment(key string) error {
startTime := time.Now()
klog.V(4).Infof("Started syncing deployment %q (%v)", key, startTime)
defer func() {
klog.V(4).Infof("Finished syncing deployment %q (%v)", key, time.Since(startTime))
}()
namespace, name, err := cache.SplitMetaNamespaceKey(key)
if err != nil {
return err
}
deployment, err := dc.dLister.Deployments(namespace).Get(name)
if errors.IsNotFound(err) {
klog.V(2).Infof("Deployment %v has been deleted", key)
return nil
}
if err != nil {
return err
}
// Deep-copy otherwise we are mutating our cache.
// TODO: Deep-copy only when needed.
d := deployment.DeepCopy()
everything := metav1.LabelSelector{}
if reflect.DeepEqual(d.Spec.Selector, &everything) {
// deployment必须包含selector标签
dc.eventRecorder.Eventf(d, v1.EventTypeWarning, "SelectingAll", "This deployment is selecting all pods. A non-empty selector is required.")
if d.Status.ObservedGeneration < d.Generation {
d.Status.ObservedGeneration = d.Generation
dc.client.AppsV1().Deployments(d.Namespace).UpdateStatus(d)
}
return nil
}
// 获取deployment所控制的replicaSet
rsList, err := dc.getReplicaSetsForDeployment(d)
if err != nil {
return err
}
// 获取所有的pod,map结构,按replicaSet分组,key是rs。
// 检查deployment在重建的过程中是否还存在旧版本(未更新)的pod
podMap, err := dc.getPodMapForDeployment(d, rsList)
if err != nil {
return err
}
if d.DeletionTimestamp != nil {
return dc.syncStatusOnly(d, rsList)
}
// 检查deployment是否为pause暂停状态,pause状态则调用sync方法同步deployment
if err = dc.checkPausedConditions(d); err != nil {
return err
}
if d.Spec.Paused {
return dc.sync(d, rsList)
}
// 判断本次deployment事件是否是一个回滚事件
// 一旦底层的rs更新到了一个新的版本,就无法自动执行回滚了,因此,直到下一次队列中再次出现此deployment且不为rollback状态时,才能无虞地触发更新rs。所以,这里再进行一次判断,如果deployment带有回滚标记,那么先执行rs的回滚。
if getRollbackTo(d) != nil {
return dc.rollback(d, rsList)
}
// 判断本次deployment事件是否是一个scale事件,是则调用sync方法同步deployment
scalingEvent, err := dc.isScalingEvent(d, rsList)
if err != nil {
return err
}
if scalingEvent {
return dc.sync(d, rsList)
}
// 更新deployment,视Deployment.Spec.Strategy指定的更新策略类型来执行相应的更新操作
// 1.如果是rolloutRecreate类型,则一次性杀死pod再重建
// 2.如果是rolloutRolling类型,则滚动更新pod
switch d.Spec.Strategy.Type {
case apps.RecreateDeploymentStrategyType:
return dc.rolloutRecreate(d, rsList, podMap)
case apps.RollingUpdateDeploymentStrategyType:
return dc.rolloutRolling(d, rsList)
}
return fmt.Errorf("unexpected deployment strategy type: %s", d.Spec.Strategy.Type)
}
暂停和扩(缩)容(/删除)
dc.sync方法这里出现了两次,分别在pause状态和scaling状态调用,比较关键,分析一下sync方法的内容。
pkg/controller/deployment/sync.go:48
func (dc *DeploymentController) sync(d *apps.Deployment, rsList []*apps.ReplicaSet) error {
// 展开查看代码,可以知道,这里的newRS,指的是找到模板hash值与当前的d Deployment 模板hash值相同的rs,oldRSs则是所有的历史版本的rs
newRS, oldRSs, err := dc.getAllReplicaSetsAndSyncRevision(d, rsList, false)
if err != nil {
return err
}
// 对比最新的rs和之前的rs,如果需要scale缩扩容,则执行scale方法
if err := dc.scale(d, newRS, oldRSs); err != nil {
// If we get an error while trying to scale, the deployment will be requeued
// so we can abort this resync
return err
}
// pause状态,且不处于回滚状态的deployment,进行清理(根据指定的保存历史版本数上限,清理超出限制的历史版本)
if d.Spec.Paused && getRollbackTo(d) == nil {
if err := dc.cleanupDeployment(oldRSs, d); err != nil {
return err
}
}
allRSs := append(oldRSs, newRS)
// 同步deployment状态
return dc.syncDeploymentStatus(allRSs, newRS, d)
}
来看看dc.scale()方法:
pkg/controller/deployment/sync.go:289
func (dc *DeploymentController) scale(deployment *apps.Deployment, newRS *apps.ReplicaSet, oldRSs []*apps.ReplicaSet) error {
// FindActiveOrLatest方法返回值:如果此时只有一个活跃的rs,那么就返回这个rs,如果不止,那么就找出revision最新的rs返回
if activeOrLatest := deploymentutil.FindActiveOrLatest(newRS, oldRSs); activeOrLatest != nil {
if *(activeOrLatest.Spec.Replicas) == *(deployment.Spec.Replicas) {
// 如果rs已经和deployment指定的副本数一致,直接return
return nil
}
_, _, err := dc.scaleReplicaSetAndRecordEvent(activeOrLatest, *(deployment.Spec.Replicas), deployment)
return err
}
// 如果最新的rs的已经收敛到了deployment的期望状态,则旧rs需要被完全scale down缩容删除掉。
if deploymentutil.IsSaturated(deployment, newRS) {
for _, old := range controller.FilterActiveReplicaSets(oldRSs) {
if _, _, err := dc.scaleReplicaSetAndRecordEvent(old, 0, deployment); err != nil {
return err
}
}
return nil
}
// 在滚动更新的过程中,需要控制旧rs与新rs所控制的模板pod的数量的总和,多出的pod数量不能超过MaxSurge数,因此是滚动更新的过程中,旧rs和新rs控制得pod数量必然是一个此消彼长的过程
if deploymentutil.IsRollingUpdate(deployment) {
allRSs := controller.FilterActiveReplicaSets(append(oldRSs, newRS))
allRSsReplicas := deploymentutil.GetReplicaCountForReplicaSets(allRSs)
allowedSize := int32(0)
if *(deployment.Spec.Replicas) > 0 {
allowedSize = *(deployment.Spec.Replicas) + deploymentutil.MaxSurge(*deployment)
}
// 可以增加或删除的pod数量,结果正数则代表可以继续新增pod,结果为负数则代表需要删除pod了
deploymentReplicasToAdd := allowedSize - allRSsReplicas
var scalingOperation string
switch {
case deploymentReplicasToAdd > 0:
// 如果是扩容,那么把所有的rs按时间从最新到最旧的顺序排序
sort.Sort(controller.ReplicaSetsBySizeNewer(allRSs))
scalingOperation = "up"
case deploymentReplicasToAdd < 0:
// 如果是缩容,那么把所有的rs按时间从最旧到最新的顺序排序
sort.Sort(controller.ReplicaSetsBySizeOlder(allRSs))
scalingOperation = "down"
}
// 遍历每一个rs, 用map保存此rs应该达到的pod的数量(等于当前数量+需scale数量)
deploymentReplicasAdded := int32(0)
nameToSize := make(map[string]int32)
for i := range allRSs {
rs := allRSs[i]
if deploymentReplicasToAdd != 0 {
// 计算当前rs需scale的数量
proportion := deploymentutil.GetProportion(rs, *deployment, deploymentReplicasToAdd, deploymentReplicasAdded)
// 总pod数量等于当前数量+scale数量
nameToSize[rs.Name] = *(rs.Spec.Replicas) + proportion
deploymentReplicasAdded += proportion
} else {
nameToSize[rs.Name] = *(rs.Spec.Replicas)
}
}
// Update all replica sets
for i := range allRSs {
rs := allRSs[i]
// Add/remove any leftovers to the largest replica set.
// 如果还有各rs加起来都未消化完的pod,则交给上面排序后的第一个rs(最新或最旧的rs)。
if i == 0 && deploymentReplicasToAdd != 0 {
leftover := deploymentReplicasToAdd - deploymentReplicasAdded
nameToSize[rs.Name] = nameToSize[rs.Name] + leftover
if nameToSize[rs.Name] < 0 {
nameToSize[rs.Name] = 0
}
}
// 把这个rs scale到它应该达到的数量
if _, _, err := dc.scaleReplicaSet(rs, nameToSize[rs.Name], deployment, scalingOperation); err != nil {
// Return as soon as we fail, the deployment is requeued
return err
}
}
}
return nil
}
syncDeploymentStatus函数
在完成rs的scale和pause状态的逻辑处理后,deployment的状态也需要与最新的rs同步,因此这个函数就是用来同步deployment的状态的。
func (dc *DeploymentController) syncDeploymentStatus(allRSs []*apps.ReplicaSet, newRS *apps.ReplicaSet, d *apps.Deployment) error {
newStatus := calculateStatus(allRSs, newRS, d)
if reflect.DeepEqual(d.Status, newStatus) {
return nil
}
newDeployment := d
newDeployment.Status = newStatus
_, err := dc.client.AppsV1().Deployments(newDeployment.Namespace).UpdateStatus(newDeployment)
return err
}
这个函数主要用来更新deployment的status字段的内容,例如版本、副本数、可用副本数、更新副本数等等。
整个扩容的过程涉及所有rs的操作,可能很容易混淆,但其实只要记住在99%的情况下,deployment只有一个活跃状态的rs,即newRS,大部分操作都是针对这个newRS做的,那么上面的过程就容易理解很多了。
滚动更新
Deployment更新策略分为滚动更新和一次性更新,更新方式其实都是类似,只是一个是分批式,一个是全量式,这里看下滚动更新的代码。
deployment 的spec字段内的内容一旦发生变化,就会触发rs的更新,生成新版本的rs,并且基于新rs进行副本扩容,旧版本的rs则会缩容。
pkg/controller/deployment/deployment_controller.go:644
==> pkg/controller/deployment/rolling.go:31
func (dc *DeploymentController) rolloutRolling(d *apps.Deployment, rsList []*apps.ReplicaSet) error {
// 获取新的rs,如果没有新的rs则创建newRS
newRS, oldRSs, err := dc.getAllReplicaSetsAndSyncRevision(d, rsList, true)
if err != nil {
return err
}
allRSs := append(oldRSs, newRS)
// 对比判断newRS是否需要扩容(新rs管理的pod是否已达到目标数量)
scaledUp, err := dc.reconcileNewReplicaSet(allRSs, newRS, d)
if err != nil {
return err
}
if scaledUp {
// 扩容完毕,更新deployment的status
return dc.syncRolloutStatus(allRSs, newRS, d)
}
// 对比判断oldRS是否需要缩容(旧rs管理的pod是否已经全部终结)
scaledDown, err := dc.reconcileOldReplicaSets(allRSs, controller.FilterActiveReplicaSets(oldRSs), newRS, d)
if err != nil {
return err
}
if scaledDown {
// 缩容完毕,更新deployment的status
return dc.syncRolloutStatus(allRSs, newRS, d)
}
// deployment 进入complete状态,根据revision历史版本数限制,清除旧的rs
if deploymentutil.DeploymentComplete(d, &d.Status) {
if err := dc.cleanupDeployment(oldRSs, d); err != nil {
return err
}
}
// 更新deployment的status
return dc.syncRolloutStatus(allRSs, newRS, d)
}
reconcileNewReplicaSet函数:
这个函数返回bool值,即是否应该扩容newRS的bool值
func (dc *DeploymentController) reconcileNewReplicaSet(allRSs []*apps.ReplicaSet, newRS *apps.ReplicaSet, deployment *apps.Deployment) (bool, error) {
if *(newRS.Spec.Replicas) == *(deployment.Spec.Replicas) {
// deployment replicas 和newRS replicas相等,则说明new rs已经无需扩容
return false, nil
}
if *(newRS.Spec.Replicas) > *(deployment.Spec.Replicas) {
// newRS replicas > deployment replicas,则说明newRS需要缩容,返回值scaled此时值应当是false
scaled, _, err := dc.scaleReplicaSetAndRecordEvent(newRS, *(deployment.Spec.Replicas), deployment)
return scaled, err
}
// newRS replicas < deployment replicas,则使用NewRSNewReplicas方法计算newRS此时应用拥有的pod副本的数量
newReplicasCount, err := deploymentutil.NewRSNewReplicas(deployment, allRSs, newRS)
if err != nil {
return false, err
}
// 返回值scaled此时值应当是true
scaled, _, err := dc.scaleReplicaSetAndRecordEvent(newRS, newReplicasCount, deployment)
return scaled, err
}
NewRSNewReplicas函数:
计算newRS此时应该有的副本数量的函数
func NewRSNewReplicas(deployment *apps.Deployment, allRSs []*apps.ReplicaSet, newRS *apps.ReplicaSet) (int32, error) {
switch deployment.Spec.Strategy.Type {
// 滚动更新时
case apps.RollingUpdateDeploymentStrategyType:
// Check if we can scale up.
maxSurge, err := intstrutil.GetValueFromIntOrPercent(deployment.Spec.Strategy.RollingUpdate.MaxSurge, int(*(deployment.Spec.Replicas)), true)
if err != nil {
return 0, err
}
// 当前的副本数(当前值) = 所有版本的rs管理的pod数量的总和
currentPodCount := GetReplicaCountForReplicaSets(allRSs)
// 最多允许同时存在的副本数(最大值) = 指定副本数 + maxSurge的副本数(整数或者比例计算)
maxTotalPods := *(deployment.Spec.Replicas) + int32(maxSurge)
// 如果当前值比最大值还大,那么说明不能再扩容了,直接返回最新的newRS.Spec.Replicas
if currentPodCount >= maxTotalPods {
return *(newRS.Spec.Replicas), nil
}
// 否则,可扩容值 = 最大值 - 当前值
scaleUpCount := maxTotalPods - currentPodCount
// 但每一个版本的rs管理的副本数量,不能超过deployment所指定的副本数量,只有新旧版本的rs加起来的副本数可以突破到maxSurge的上限。因此,这里的可扩容值要取这两个值之间的最小值。
scaleUpCount = int32(integer.IntMin(int(scaleUpCount), int(*(deployment.Spec.Replicas)-*(newRS.Spec.Replicas))))
// 此时newRS应有的副本数 = 当前值 + 可扩容值
return *(newRS.Spec.Replicas) + scaleUpCount, nil
case apps.RecreateDeploymentStrategyType:
// 非滚动更新时,newRS的应用副本数 = deployment.Spec.Replicas,无弹性
return *(deployment.Spec.Replicas), nil
default:
return 0, fmt.Errorf("deployment type %v isn't supported", deployment.Spec.Strategy.Type)
}
}
reconcileOldReplicaSets函数
这个函数返回bool值,即是否应该缩容oldRSs的bool值
func (dc *DeploymentController) reconcileOldReplicaSets(allRSs []*apps.ReplicaSet, oldRSs []*apps.ReplicaSet, newRS *apps.ReplicaSet, deployment *apps.Deployment) (bool, error) {
oldPodsCount := deploymentutil.GetReplicaCountForReplicaSets(oldRSs)
if oldPodsCount == 0 {
// 已经缩容完毕,直接返回
return false, nil
}
// 当前所有的pod的数量(当前值)
allPodsCount := deploymentutil.GetReplicaCountForReplicaSets(allRSs)
klog.V(4).Infof("New replica set %s/%s has %d available pods.", newRS.Namespace, newRS.Name, newRS.Status.AvailableReplicas)
// deployment 指定的最大不可用的副本数(最大不可用值)
maxUnavailable := deploymentutil.MaxUnavailable(*deployment)
// Check if we can scale down. We can scale down in the following 2 cases:
// * Some old replica sets have unhealthy replicas, we could safely scale down those unhealthy replicas since that won't further
// increase unavailability.
// * New replica set has scaled up and it's replicas becomes ready, then we can scale down old replica sets in a further step.
//
// maxScaledDown := allPodsCount - minAvailable - newReplicaSetPodsUnavailable
// take into account not only maxUnavailable and any surge pods that have been created, but also unavailable pods from
// the newRS, so that the unavailable pods from the newRS would not make us scale down old replica sets in a further
// step(that will increase unavailability).
//
// Concrete example:
//
// * 10 replicas
// * 2 maxUnavailable (absolute number, not percent)
// * 3 maxSurge (absolute number, not percent)
//
// case 1:
// * Deployment is updated, newRS is created with 3 replicas, oldRS is scaled down to 8, and newRS is scaled up to 5.
// * The new replica set pods crashloop and never become available.
// * allPodsCount is 13. minAvailable is 8. newRSPodsUnavailable is 5.
// * A node fails and causes one of the oldRS pods to become unavailable. However, 13 - 8 - 5 = 0, so the oldRS won't be scaled down.
// * The user notices the crashloop and does kubectl rollout undo to rollback.
// * newRSPodsUnavailable is 1, since we rolled back to the good replica set, so maxScaledDown = 13 - 8 - 1 = 4. 4 of the crashlooping pods will be scaled down.
// * The total number of pods will then be 9 and the newRS can be scaled up to 10.
//
// case 2:
// Same example, but pushing a new pod template instead of rolling back (aka "roll over"):
// * The new replica set created must start with 0 replicas because allPodsCount is already at 13.
// * However, newRSPodsUnavailable would also be 0, so the 2 old replica sets could be scaled down by 5 (13 - 8 - 0), which would then
// allow the new replica set to be scaled up by 5.
// Available指的是就绪探针结果为true的副本,若默认未指定就绪探针,则pod running之后自动视就绪为true
// 最小可用副本数(至少可用数)
minAvailable := *(deployment.Spec.Replicas) - maxUnavailable
// newRs不可用数
newRSUnavailablePodCount := *(newRS.Spec.Replicas) - newRS.Status.AvailableReplicas
// 最大可缩容数 = 总数 - 最小可用数 - newRS不可用数(为了保证最小可用数,因此此时newRS的不可用副本不能参与这个计算)
maxScaledDown := allPodsCount - minAvailable - newRSUnavailablePodCount
if maxScaledDown <= 0 {
return false, nil
}
// oldRS里不健康的副本,无论如何都是需要清除的
// and cause timeout. See https://github.com/kubernetes/kubernetes/issues/16737
oldRSs, cleanupCount, err := dc.cleanupUnhealthyReplicas(oldRSs, deployment, maxScaledDown)
if err != nil {
return false, nil
}
klog.V(4).Infof("Cleaned up unhealthy replicas from old RSes by %d", cleanupCount)
// 还要对比最大可缩容数和deployment指定的最大同时不可用副本数,这两者之间的最小值,才是可缩容数量
allRSs = append(oldRSs, newRS)
scaledDownCount, err := dc.scaleDownOldReplicaSetsForRollingUpdate(allRSs, oldRSs, deployment)
if err != nil {
return false, nil
}
klog.V(4).Infof("Scaled down old RSes of deployment %s by %d", deployment.Name, scaledDownCount)
// oldRS里不健康的副本,无论如何都是需要清除的
totalScaledDown := cleanupCount + scaledDownCount
// 判断缩容数是否大于0
return totalScaledDown > 0, nil
}
中间的英文注释里的举例说明非常详细,可以看一下注释。
syncRolloutStatus函数
这个函数主要用于更新deployment的status字段和其中的condition字段。
func (dc *DeploymentController) syncRolloutStatus(allRSs []*apps.ReplicaSet, newRS *apps.ReplicaSet, d *apps.Deployment) error {
newStatus := calculateStatus(allRSs, newRS, d)
if !util.HasProgressDeadline(d) {
util.RemoveDeploymentCondition(&newStatus, apps.DeploymentProgressing)
}
currentCond := util.GetDeploymentCondition(d.Status, apps.DeploymentProgressing)
/**
判断deployment是否为complete状态,条件有多个:
1. newRS.replicas = newRS.Status.UpdatedReplicas 说明newRS的副本更新已全部完成
2. newRS.status.condition.reason = miniumReplicasAvailable
**/
isCompleteDeployment := newStatus.Replicas == newStatus.UpdatedReplicas && currentCond != nil && currentCond.Reason == util.NewRSAvailableReason
// 未达到complete状态的deployment,才进行下面的检查
if util.HasProgressDeadline(d) && !isCompleteDeployment {
switch {
case util.DeploymentComplete(d, &newStatus):
// Update the deployment conditions with a message for the new replica set that
// was successfully deployed. If the condition already exists, we ignore this update.
msg := fmt.Sprintf("Deployment %q has successfully progressed.", d.Name)
if newRS != nil {
msg = fmt.Sprintf("ReplicaSet %q has successfully progressed.", newRS.Name)
}
condition := util.NewDeploymentCondition(apps.DeploymentProgressing, v1.ConditionTrue, util.NewRSAvailableReason, msg)
util.SetDeploymentCondition(&newStatus, *condition)
case util.DeploymentProgressing(d, &newStatus):
// If there is any progress made, continue by not checking if the deployment failed. This
// behavior emulates the rolling updater progressDeadline check.
msg := fmt.Sprintf("Deployment %q is progressing.", d.Name)
if newRS != nil {
msg = fmt.Sprintf("ReplicaSet %q is progressing.", newRS.Name)
}
condition := util.NewDeploymentCondition(apps.DeploymentProgressing, v1.ConditionTrue, util.ReplicaSetUpdatedReason, msg)
// Update the current Progressing condition or add a new one if it doesn't exist.
// If a Progressing condition with status=true already exists, we should update
// everything but lastTransitionTime. SetDeploymentCondition already does that but
// it also is not updating conditions when the reason of the new condition is the
// same as the old. The Progressing condition is a special case because we want to
// update with the same reason and change just lastUpdateTime iff we notice any
// progress. That's why we handle it here.
if currentCond != nil {
if currentCond.Status == v1.ConditionTrue {
condition.LastTransitionTime = currentCond.LastTransitionTime
}
util.RemoveDeploymentCondition(&newStatus, apps.DeploymentProgressing)
}
util.SetDeploymentCondition(&newStatus, *condition)
case util.DeploymentTimedOut(d, &newStatus):
// Update the deployment with a timeout condition. If the condition already exists,
// we ignore this update.
msg := fmt.Sprintf("Deployment %q has timed out progressing.", d.Name)
if newRS != nil {
msg = fmt.Sprintf("ReplicaSet %q has timed out progressing.", newRS.Name)
}
condition := util.NewDeploymentCondition(apps.DeploymentProgressing, v1.ConditionFalse, util.TimedOutReason, msg)
util.SetDeploymentCondition(&newStatus, *condition)
}
}
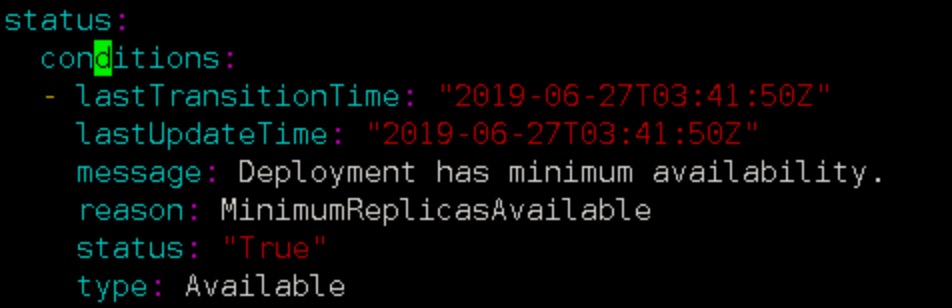
DeploymentCondition在这里面反复出现,便于理解,参照一个正常状态的deployment condition样例:
总结
滚动更新过程中主要是通过调用reconcileNewReplicaSet函数对 newRS 扩容,调用 reconcileOldReplicaSets函数 对 oldRSs缩容,按照 maxSurge 和 maxUnavailable 的约束,计时器间隔1s反复执行、收敛、修正,最终达到期望状态,完成更新。
总结
Deployment的回滚、扩(缩)容、暂停、更新等操作,主要是通过修改rs来完成的。其中,rs的版本控制、replicas数量控制是其最核心也是难以理解的地方,但是只要记住99%的时间里deployment对应的活跃的rs只有一个,只有更新时才会出现2个rs,极少数情况下(短时间重复更新)才会出现2个以上的rs,对于上面源码的理解就会容易许多。
另外,从上面这么多步骤的拆解也可以发现,deployment的更新实际基本不涉及对pod的直接操作,因此,本章后续的章节会分析一下replicaSet controller是怎么和pod进行管理交互的。